
Scaling a Monolithic Architecture to Billions: PostgreSQL, Django, No Kubernetes
Every few years the industry rediscovers the same lesson. A small team ships a product on a boring stack, the product takes off, and suddenly the engineering conversation turns to microservices, service meshes, and container orchestration. The assumption is that real scale demands a distributed architecture with dozens of services. Yet some of the largest consumer products ever built reached enormous scale on a monolithic architecture: a single application written in Python, backed by PostgreSQL, fronted by Memcached, and coordinated by a task queue. No Kubernetes. No microservices. Just a well-run monolith.
This post is a case study in how to scale a monolith without reaching for the heavy machinery. It draws on publicly documented architectures, most notably the early engineering write-ups from Instagram, whose team scaled a Django and PostgreSQL application to hundreds of millions of users with a famously small engineering staff. The point is not that a monolithic architecture is always right or that microservices are wrong. The point is that the bottleneck you actually hit at scale is rarely the one the conference talks warn you about.
The Monolithic Architecture Stack That Refuses to Die
The components in the title are not exotic. They are the same pieces a junior engineer would reach for to build a side project, which is exactly why they are underrated. This is what a monolithic architecture actually looks like in production once you strip away the marketing around distributed systems.
PostgreSQL is the system of record. Django is the application layer, handling routing, ORM access, templating, and business logic in one deployable unit. Memcached sits in front of the database to absorb read traffic. RabbitMQ (or a comparable broker) decouples slow work from the request path. That is the entire backbone, and variations of it run some of the highest-traffic sites on the internet.
What makes this stack durable is that each layer has a single, well-understood job. When something gets slow, you can reason about which layer is responsible without tracing a request across a dozen network hops. Observability in a monolith is local. That is a real operational advantage when you are debugging at three in the morning.
Why Teams Reach for Microservices Too Early
Before looking at how to scale the monolith, it is worth being honest about why teams abandon it. The reasons are usually organizational rather than technical.
Microservices solve a people problem first and a scaling problem second. When you have fifty teams that all want to deploy independently, splitting the codebase along team boundaries reduces coordination cost. That is a legitimate reason. But a ten-person team does not have a coordination problem. It has a focus problem, and splitting into services multiplies the operational surface area without buying anything. You trade in-process function calls for network calls, local transactions for distributed sagas, and a single deploy for an orchestration platform.
The cost of that trade is real. Distributed systems introduce partial failure, eventual consistency, and debugging that spans process boundaries. As Martin Fowler has argued in his writing on the "monolith first" approach, most systems should start as a monolith and only decompose once the boundaries are well understood. Premature decomposition locks in the wrong boundaries and is far harder to undo than to avoid.
For a deeper treatment of when the split actually makes sense, our modular monolith vs microservices decision framework walks through the specific signals that justify the move.
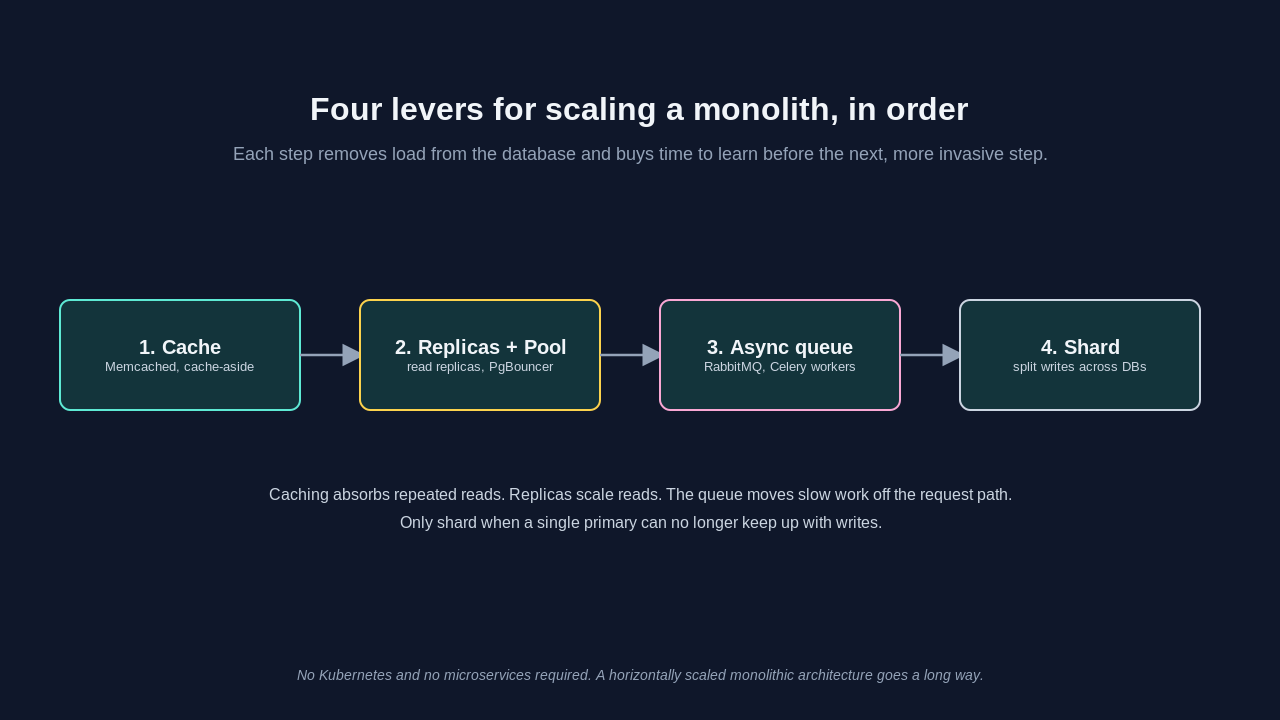
Lever One: Cache Aggressively With Memcached
The first thing that breaks under load is the database, and the first fix is to stop asking it the same question repeatedly. Memcached is an in-memory key-value store that holds the results of expensive reads so the database never sees them twice.
The pattern is cache-aside. The application checks the cache first. On a miss, it reads the database, writes the result back to the cache, and returns it. On a hit, the database is never touched.
import hashlib
from django.core.cache import cache
from myapp.models import Post
def get_post(post_id):
key = f"post:{post_id}"
cached = cache.get(key)
if cached is not None:
return cached
post = Post.objects.get(pk=post_id)
cache.set(key, post, timeout=3600) # one hour
return post
def invalidate_post(post_id):
cache.delete(f"post:{post_id}")The hard part of caching is not the read. It is invalidation. When the underlying row changes, the cache entry must be removed or updated, or users will see stale data. A disciplined approach is to invalidate on write inside the same code path that mutates the row, so the cache and the database never drift for long.
At very high scale, Memcached itself becomes a fleet. You run many instances and shard keys across them with consistent hashing so that adding or removing a node only remaps a small fraction of keys. This is the same idea behind distributing any large dataset, covered in more depth in our writing on consistent hashing and data partitioning.
Lever Two: Read Replicas and Connection Pooling
Caching removes repeated reads, but the database still handles every write and every cache miss. The next lever is to scale reads horizontally with replication.
PostgreSQL supports streaming replication, where one primary handles writes and one or more replicas receive a continuous stream of changes. The application sends writes to the primary and spreads reads across the replicas. Django supports this directly through database routers.
import random
class PrimaryReplicaRouter:
replicas = ["replica_1", "replica_2"]
def db_for_read(self, model, **hints):
return random.choice(self.replicas)
def db_for_write(self, model, **hints):
return "default" # the primary
def allow_relation(self, obj1, obj2, **hints):
return TrueReplication introduces replication lag. A write committed on the primary takes a short time to appear on the replicas. If a user updates their profile and then immediately reads it from a replica, they may see the old value. The usual fix is read-your-writes routing: for a short window after a write, route that user's reads to the primary.
The second database problem at scale is connection exhaustion. Each PostgreSQL connection costs memory, and a fleet of application servers can easily open more connections than the database can hold. A connection pooler such as PgBouncer sits between the application and the database, multiplexing thousands of client connections onto a small pool of real ones.
Lever Three: Move Slow Work Off the Request Path
A web request should do the minimum work required to return a response. Anything that can happen later should happen later. This is where RabbitMQ and a task worker such as Celery earn their place.
When a user uploads a photo, the request should save the file and return immediately. Generating thumbnails, updating followers' feeds, running content checks, and sending notifications all happen asynchronously. The web server publishes a message to the broker and moves on. A separate pool of worker processes consumes those messages and does the heavy lifting.
from celery import shared_task
@shared_task(bind=True, max_retries=3)
def process_upload(self, photo_id):
try:
generate_thumbnails(photo_id)
fan_out_to_followers(photo_id)
enqueue_safety_scan(photo_id)
except TransientError as exc:
# retry with exponential backoff
raise self.retry(exc=exc, countdown=2 ** self.request.retries)This pattern keeps the request path fast and predictable. It also gives you a natural place to apply backpressure. If a downstream system slows down, messages queue up in the broker instead of timing out user requests. You can scale workers independently of web servers, which is a far cheaper and simpler form of independent scaling than splitting the application into services.
The fan-out problem, where one action must update many other users' data, is one of the classic challenges of social applications. Whether you fan out on write or compute on read is a genuine design decision with real tradeoffs, and the right answer depends on your read-to-write ratio.
Lever Four: Shard the Database When a Replica Is Not Enough
Read replicas scale reads, but a single primary still has to absorb every write. When write volume outgrows one machine, you shard: you split the data across multiple independent PostgreSQL servers, each owning a slice of the keyspace.
The Instagram team documented an elegant approach using logical shards mapped onto a smaller number of physical databases, with IDs generated to encode their shard. Generating unique IDs that sort roughly by time and carry their shard location lets the application route any row to the correct database without a central lookup. The structure of such an ID typically combines a timestamp, a shard identifier, and a per-shard sequence number into a single 64-bit integer.
41 bits: milliseconds since a custom epoch
13 bits: logical shard id
10 bits: per-shard auto-increment sequence
----------------------------------------
64 bits total, time-sortable, shard-routable
Sharding is the most invasive lever, and you should delay it as long as caching, replicas, and pooling are still buying you headroom. Once you shard, cross-shard queries and transactions become expensive, so the schema and access patterns have to be designed around the shard key. This is precisely why you do not shard early: you want to understand your access patterns deeply before you bake them into the physical layout.
Why No Kubernetes Was Fine
Container orchestration is excellent for managing many heterogeneous services with complex scheduling needs. A monolith does not have that shape. It is a handful of identical stateless application servers behind a load balancer, plus a few stateful systems (PostgreSQL, Memcached, the broker) that you generally do not want an orchestrator rescheduling out from under you.
For a uniform fleet of stateless app servers, an autoscaling group and a load balancer do the job with a fraction of the operational complexity. You add servers when CPU rises and remove them when it falls. There is no control plane to operate, no networking abstraction to debug, no new failure mode to learn. The simplicity compounds: fewer moving parts means fewer incidents and a smaller on-call burden, which matters enormously for a small team.
This is the throughline of the entire architecture. Every choice optimizes for a small team's ability to understand, operate, and debug the system. That is a feature, not a limitation. Teams routinely underestimate how much velocity they lose to operational complexity they adopted before they needed it.
When You Genuinely Should Decompose
None of this is an argument that the monolith scales forever or fits every situation. There are real signals that justify splitting it up.
You should consider decomposing when deploy contention becomes a tax, meaning teams are blocked waiting on each other's releases. You should consider it when one part of the system has wildly different scaling or reliability requirements than the rest, such as a real-time messaging subsystem living inside a content app. You should consider it when distinct parts genuinely need different technology stacks. And you should consider it when the codebase has grown large enough that the cognitive load of the whole exceeds any one engineer's grasp.
The mistake is treating those signals as a reason to start with microservices rather than a reason to evolve toward them. As covered in our piece on why teams are leaving microservices in 2026, a surprising number of organizations are consolidating back into modular monoliths after discovering the distributed version cost more than it returned. When the time does come, the path from a well-structured monolith is itself a project worth planning, which you can read more about on the Levelop blog.
Frequently Asked Questions
Can a monolith really handle billions of users?
A single application process cannot, but a horizontally scaled fleet of identical monolith instances, backed by a cached and replicated database, demonstrably can. Publicly documented systems such as Instagram reached hundreds of millions of users on a Django and PostgreSQL architecture. The monolith refers to the codebase being one deployable unit, not to running on one machine. You still run many copies behind a load balancer.
What is the first thing to optimize when a monolith gets slow?
Almost always the database. Start by finding the slow queries and the most frequent reads, then put a cache such as Memcached in front of those reads. Caching the hottest objects typically removes the majority of database load with very little code change, which makes it the highest-return first move before you consider replicas or sharding.
Do I need Kubernetes to scale a web application?
No. Kubernetes is valuable when you operate many different services with complex scheduling needs. A monolith is a uniform fleet of stateless servers, which an autoscaling group and a load balancer handle with far less operational complexity. Adopt orchestration when the shape of your system actually calls for it, not by default.
When should I move from read replicas to sharding?
Move to sharding only when a single primary can no longer absorb your write volume, since replicas scale reads but not writes. Exhaust caching, read replicas, and connection pooling first. Sharding is the most invasive change because it constrains your schema and access patterns around the shard key, so delay it until you deeply understand those patterns.
Is a monolithic architecture outdated in 2026?
Not at all. The industry trend has actually shifted back toward the modular monolith for many use cases, as teams account for the operational cost of distributed systems. A monolithic architecture remains the correct default for most products, with decomposition reserved for specific organizational and technical signals rather than adopted preemptively.
Closing Thoughts
The most important lesson from systems that scaled a monolith to enormous size is that scaling is a sequence of targeted, reversible moves against well-understood bottlenecks, not a wholesale architectural rewrite. Cache the hot reads. Replicate to scale reads. Pool your connections. Push slow work to a queue. Shard only when writes truly demand it. Each of these is something a small team can implement, reason about, and operate without a platform engineering org standing behind it.
If you are building toward scale, the question to keep asking is not "how do the big companies do it" but "what is my actual bottleneck right now, and what is the smallest change that removes it." For more system design deep dives, explore the Levelop blog or start practicing architecture decisions hands-on at Levelop.
References
- Instagram Engineering, "What Powers Instagram: Hundreds of Instances, Dozens of Technologies," instagram-engineering.com.
- Instagram Engineering, "Sharding & IDs at Instagram," instagram-engineering.com.
- Martin Fowler, "MonolithFirst," martinfowler.com/bliki/MonolithFirst.html.
- PostgreSQL Documentation, "High Availability, Load Balancing, and Replication," postgresql.org.
- PgBouncer Documentation, "Connection Pooling for PostgreSQL," pgbouncer.org.