Detect a Cycle in a Linked List: Fast and Slow Pointers
How do you detect a cycle in a linked list? It is one of the most common data structures interview questions at Google, Amazon, and Meta. The problem looks trivial until an interviewer adds one constraint, and how you react to that constraint says a lot about how you think.
This post covers the fast and slow pointer technique, also known as Floyd's cycle detection algorithm: why the naive approaches fall short, how the trick works, why the math is sound, and how to find the exact node where the cycle begins.
What It Means to Detect a Cycle in a Linked List
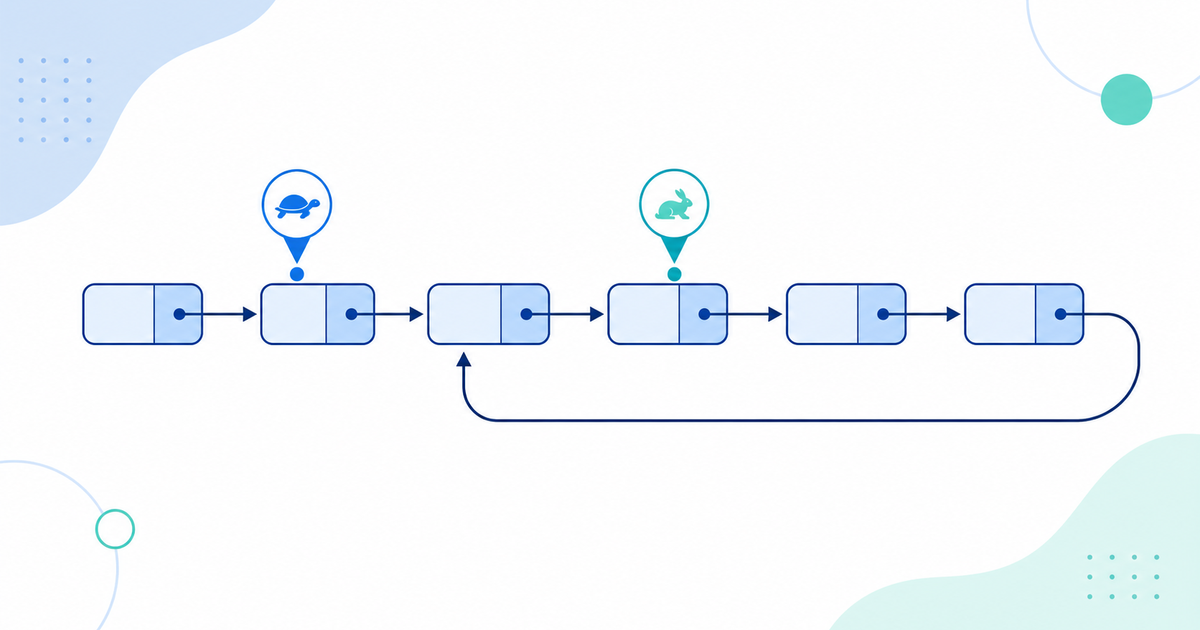
A singly linked list is a chain of nodes where each node points to the next. In a well-formed list the last node points to null, and that null tells you the list has ended. A cycle happens when some node in the list points back to an earlier node instead of forward to null. Follow the next pointers and you never reach null. You just loop forever.
Picture nodes in a line: A goes to B, B to C, C to D. If D points back to B instead of null, walking from A gives A, B, C, D, B, C, D, and so on without end. That back-pointer is the cycle, and B is where the cycle begins. To detect a cycle in a linked list is to answer one question: does following the pointers loop, or does it terminate at null?
Why the Obvious Solutions Fall Short
Two ideas come to mind first. The first is a hash set: walk the list, store every node you visit, and before moving on check whether you have seen the current node before. If you have, there is a cycle. This works in O(n) time but uses O(n) extra memory. For a list with a million nodes, you hold a million references.
The second idea is to mark each node in the list as visited by setting a flag. This mutates the input, which is usually not allowed and is bad practice. The constraint interviewers almost always add is constant extra space: no hash set, no mutation. That single requirement rules out both solutions and pushes you toward the two pointer technique.
The Fast and Slow Pointer Technique
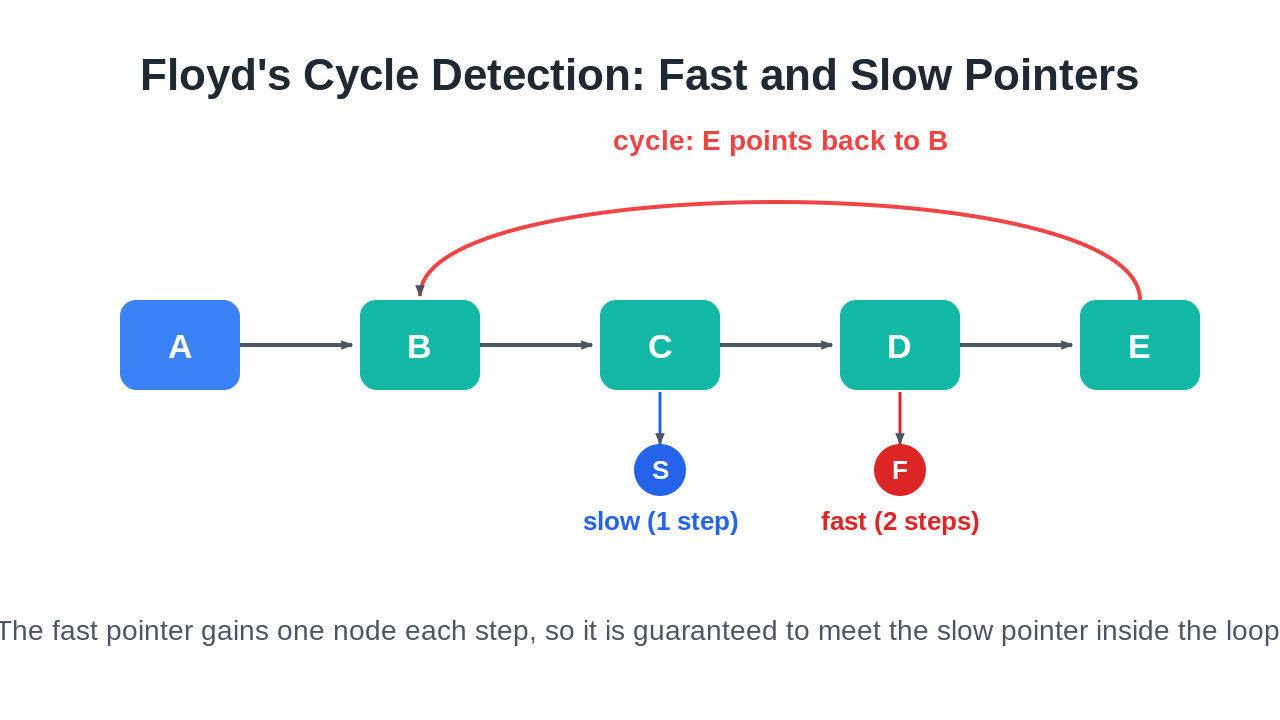
Floyd's algorithm, nicknamed the tortoise and the hare, solves the problem with two pointers and no extra memory. Start both pointers at the head. The slow pointer moves one step at a time. The fast pointer moves two steps at a time. Then let them run.
If there is no cycle, the fast pointer reaches null and you are done. If there is a cycle, the fast pointer keeps lapping the loop and, because it gains one node on the slow pointer every step, it eventually lands on the same node. The two pointers meet, and that meeting proves a cycle exists.
Could the fast pointer jump over the slow pointer and miss it? No. Once both are inside the loop, the gap between them shrinks by exactly one node each step. A gap that changes by one at a time cannot skip past zero, so a meeting is guaranteed.
Writing the Cycle Detection Code
Here is the core algorithm in Python. It returns True if a cycle exists and False otherwise.
def has_cycle(head):
slow = head
fast = head
while fast and fast.next:
slow = slow.next # slow pointer moves one step
fast = fast.next.next # fast pointer moves two steps
if slow is fast: # pointers met inside the loop
return True
return False # fast reached null, no cycleTwo details matter. The loop condition checks both fast and fast.next, because the fast pointer moves two steps and would otherwise crash on the double hop. And slow is fast compares references, not values: two different nodes can hold the same value, so compare the nodes themselves. The whole thing runs in O(n) time and O(1) space.
Why the Math Works
Suppose the loop has length C. Once both pointers are inside it, treat their positions as points on a circular track of size C. The distance from the fast pointer to the slow pointer is some value between 0 and C minus 1. Each step, the fast pointer closes that distance by one, so it must reach zero within C steps. When the distance is zero the pointers share a node. The meeting is guaranteed, not luck.
Finding Where the Cycle Begins
The sharper follow-up asks for the node where the cycle starts. After the pointers meet, reset one pointer to the head and leave the other at the meeting point. Advance both one step at a time. Where they meet again is the start of the cycle.
def detect_cycle_start(head):
slow = fast = head
while fast and fast.next: # phase 1: find the meeting point
slow = slow.next
fast = fast.next.next
if slow is fast:
break
else:
return None # no cycle
slow = head # phase 2: find the entry node
while slow is not fast:
slow = slow.next
fast = fast.next
return slowWhy does this land on the entrance? The distance from the head to the cycle entrance equals the distance from the meeting point to the entrance, so two pointers moving at the same speed converge exactly at the entry node. You do not need the full derivation in an interview, but stating that equality shows you understand the why, not just the how.
Common Mistakes to Avoid
Four errors come up under pressure. Writing while fast.next without checking fast first throws a null reference error on a list with no cycle. Comparing slow.val == fast.val instead of the nodes reports false cycles when values repeat. Starting the pointers at different nodes breaks the cycle-start math. And forgetting the no-cycle exit makes the function loop forever, which is why the while fast and fast.next guard matters.
How This Connects to a Broader Pattern
The fast and slow pointer trick is not a one-off. It belongs to a family of techniques that move multiple references through a structure in a coordinated way. You will see the same shape when finding the middle of a linked list, detecting palindromes, and working through the sliding window pattern. Once you internalize it, a whole category of problems becomes routine. For the full mental model, the two pointer technique guide is the place to start.
Frequently Asked Questions
What is the time complexity of detecting a cycle in a linked list?
The time complexity is O(n), where n is the number of nodes, with O(1) extra space. The slow pointer visits at most n nodes before the fast pointer catches it, and only two variables are used. This beats the hash set approach, which has the same O(n) time complexity but O(n) space.
Why does the fast pointer move two steps instead of three?
A step difference of one shrinks the in-loop gap by exactly one each iteration, guaranteeing a meeting. Larger step sizes still detect a cycle but complicate the meeting-point math and break the clean cycle-start logic.
How do I find the node where the cycle begins?
After the pointers meet, move one pointer back to the head and advance both one step at a time. Where they meet again is the cycle start, because the distance from the head to the entrance equals the distance from the meeting point to the entrance.
Does this technique work for doubly linked lists?
Yes. The technique only follows next pointers forward, so backward pointers are ignored. The same O(n) time and O(1) space guarantees apply.
Is Floyd's algorithm the only constant-space option?
No. Brent's algorithm also uses constant space and can be faster in practice. But Floyd's tortoise and hare is the expected interview answer because it is simple to explain and prove.
Closing Thoughts
Detecting a cycle in a linked list is a small problem with a large payoff: it teaches you to question the obvious solution under a space constraint and gives you a reusable pattern. For more interview breakdowns, browse the Levelop blog.