
Dynamic Programming Basics: State + Transition, Not Memorization
Starting a Coding Patterns Series
I'm kicking off a series on coding patterns here at Levelop. The first topic: dynamic programming. If you are learning dynamic programming basics for interviews, this is the mental model I wish I had started with.
I used to think DP was about memorizing solutions. I'd grind LeetCode problems, pattern-match the answers, and pray something similar showed up in my interview. Sometimes it worked. Most of the time, I'd see a slight variation and freeze.
The shift happened when I stopped thinking of dynamic programming as a library of problems to memorize and started seeing it as two concrete steps: define a state, then write a transition. That's it. Every dynamic programming problem reduces to those two decisions.
This post is the first in a series I'm publishing at levelop.dev/blog, where I'll break down coding patterns the way I wish someone had explained them to me.
The Problem with Memorization
Here's a scene I lived through more than once. I'd memorized the Longest Increasing Subsequence solution. Clean O(n log n) approach, could write it from memory. Then an interviewer gave me a problem about scheduling jobs with deadlines and profits. "It's kind of like LIS," I thought. It wasn't. I sat there for 20 minutes trying to force a memorized template onto a problem that needed its own state definition.
Memorization fails because interviewers don't recycle LeetCode problems verbatim. They twist them. They combine two patterns. They add a constraint that makes your memorized approach break. According to data from interviewing.io, dynamic programming interview questions appear in roughly 25% of coding rounds at major tech companies. That's a lot of surface area to cover through pure memorization.
The interviewer doesn't care if you've seen the problem before. They care about watching you think. They want to see you define what information matters, set up a recurrence, and reason about correctness. That's a framework. Memorization is not a framework.
When I finally understood this, my approach to studying dynamic programming changed completely. I stopped collecting solutions and started practicing the skill of defining states from scratch. That's what I want to share in this series on Levelop.
What "State" Really Means in DP
In dynamic programming, the state is the minimum information you need to make a decision at step i. Not all the information. Not the entire history of choices. Just enough to determine what happens next.
Think of it like a snapshot. If you paused the algorithm mid-execution and someone asked "what do you need to know right now to continue correctly?" your answer is the state.
Fibonacci: The Simplest State
Start with Fibonacci. The state is dp[i] = the i-th Fibonacci number. You need nothing else. Not how you got there, not which path you took. Just the index i, and dp[i] stores the result for that subproblem.
dp[i] = dp[i-1] + dp[i-2]The state is one-dimensional. One variable (i) fully describes where you are in the problem.
Climbing Stairs: Same Structure, Different Meaning
Now take the Climbing Stairs problem. The state is dp[i] = number of ways to reach step i. The recurrence looks identical to Fibonacci:
dp[i] = dp[i-1] + dp[i-2]But notice what changed. The meaning of dp[i] is completely different. In Fibonacci, dp[i] is a value in a sequence. In Climbing Stairs, dp[i] is a count of paths. The state definition determines what your array represents, and that determines everything downstream.
The Key Insight
Before writing any code, ask yourself: "What does dp[i] represent?" If you can't answer that in one clear sentence, you're not ready to code. This is the step most people skip. They jump to the recurrence, guess at transitions, and wonder why their solution is wrong.
Skiena's The Algorithm Design Manual puts it directly: the hardest part of dynamic programming is formulating the problem as one where the optimal solution is built from optimal solutions to subproblems. That formulation is the state definition. CLRS (Introduction to Algorithms, Cormen et al.) similarly emphasizes that characterizing the structure of an optimal solution is the first step, before ever writing a recurrence.
Get the state right, and the transition often writes itself. Get it wrong, and no amount of coding will save you.
Transitions: The Recipe That Connects States
The transition is where the actual "programming" in dynamic programming happens. It's the relationship between dp[i] and the states that came before it.
For Fibonacci: dp[i] = dp[i-1] + dp[i-2]. That's the transition. It's also the recurrence relation. These are the same thing, and realizing that was a lightbulb moment for me.
Here's what tripped me up early on. For Climbing Stairs (LeetCode 70), the transition is also dp[i] = dp[i-1] + dp[i-2]. Identical formula. But the state means something completely different. In Fibonacci, dp[i] stores the i-th Fibonacci number. In Climbing Stairs, dp[i] stores the number of distinct ways to reach step i. Same transition, different state definition, different problem solved.
This pattern taught me something practical about dynamic programming problems: once you nail the state definition, the transition often writes itself. You ask "how can I reach dp[i] from smaller subproblems?" and the formula appears. If the transition feels forced or awkward, that's a signal. Your state definition is probably wrong. Go back and redefine what dp[i] actually represents.
Erik Demaine's MIT 6.006 lectures frame the dynamic programming algorithm as "careful brute force." I love that framing because it captures exactly what transitions do. You're still trying every option (brute force), but you're building on previously computed results instead of recomputing from scratch (careful). The transition is the recipe that tells you how to combine those stored results into the next answer.
One more thing worth clarifying. Memoization vs tabulation? They both implement the same state + transition logic. Memoization goes top-down (start from the big problem, recurse down, cache results). Tabulation goes bottom-up (start from the base case, build up). The state is the same. The transition is the same. The direction differs. I personally find tabulation easier to reason about because you can see the dp array filling up, but both approaches solve the same complex problem by breaking it into subproblems with identical structure. If the top-down side is where you get stuck, I walk through it slowly in memoization: turning recursion into dynamic programming.
Walking Through a Real Problem Step by Step
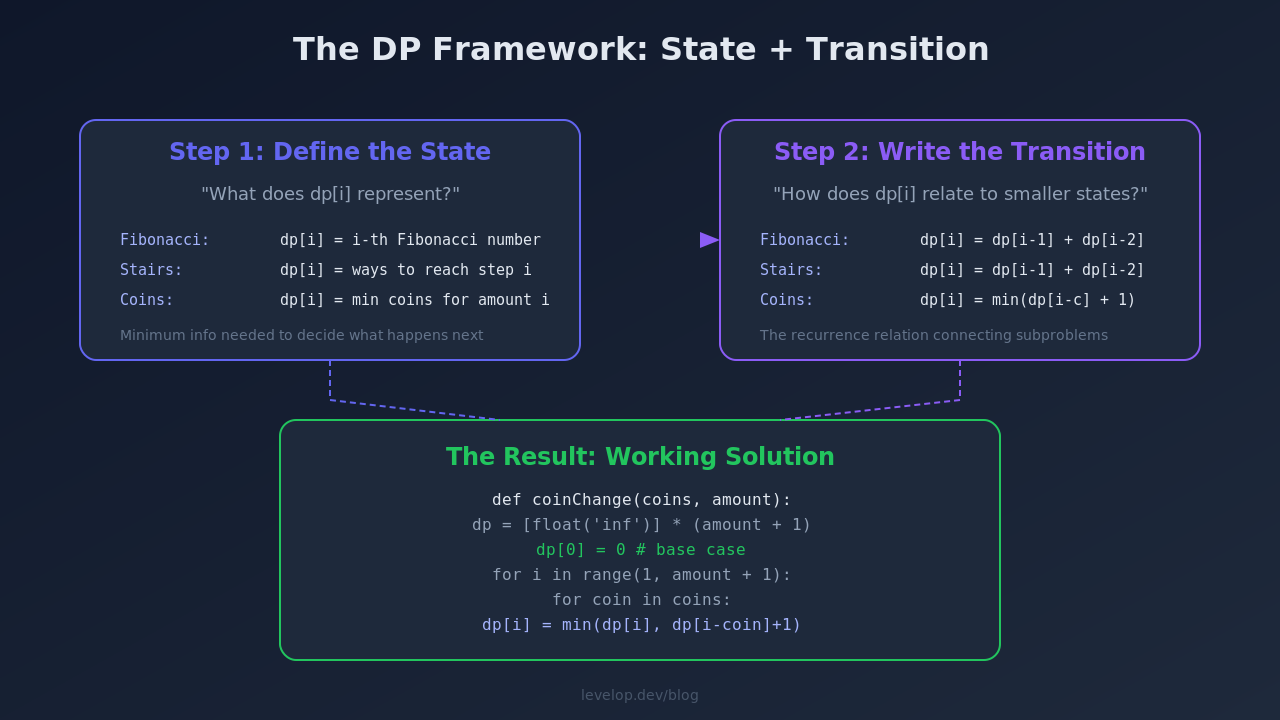
Let me work through the Coin Change problem (LeetCode 322) using only the state + transition framework. No memorized template. Just two questions.
Defining the State
I start by asking: what do I need to know at each subproblem?
"I need the minimum number of coins to make amount X."
So: dp[i] = minimum coins needed to make amount i
That's it. The state is clear, specific, and directly answers the original question when I reach dp[amount].
Finding the Transition
Now I ask: how does dp[i] relate to smaller states?
If I have a coin with value c, and I already know the optimal solution for amount i - c, then I can make amount i by using that solution plus one more coin. So for each coin c where c <= i:
dp[i] = min(dp[i], dp[i - c] + 1)The transition checks every coin and picks whichever gives the fewest total coins. This is the "careful brute force" in action.
Base Case
dp[0] = 0. Zero coins needed to make amount zero. Every other dp value starts at infinity (meaning "not yet achievable").
The Code
def coinChange(coins, amount):
# State: dp[i] = min coins to make amount i
dp = [float('inf')] * (amount + 1)
# Base case: 0 coins needed for amount 0
dp[0] = 0
# Fill states from 1 to amount
for i in range(1, amount + 1):
for coin in coins:
if coin <= i:
# Transition: use this coin, check if it's better
dp[i] = min(dp[i], dp[i - coin] + 1)
return dp[amount] if dp[amount] != float('inf') else -1Tracing Through: coins=[1,3,4], amount=6
Watch the dp array build up:
dp[0] = 0 (base case)
dp[1] = dp[0] + 1 = 1 (use coin 1)
dp[2] = dp[1] + 1 = 2 (use coin 1 twice)
dp[3] = min(dp[2]+1, dp[0]+1) = 1 (use coin 3 directly)
dp[4] = min(dp[3]+1, dp[1]+1, dp[0]+1) = 1 (use coin 4 directly)
dp[5] = min(dp[4]+1, dp[2]+1, dp[1]+1) = 2 (coin 4 + coin 1)
dp[6] = min(dp[5]+1, dp[3]+1, dp[2]+1) = 2 (coin 3 + coin 3)The answer is dp[6] = 2.
I didn't memorize this solution. I asked two questions: what's the state? What's the transition? The code wrote itself. That's what dynamic programming basics interview prep should feel like. Not pattern matching from a list of 50 problems, but understanding the framework deeply enough that new problems become solvable with the same two questions.
A Second Example: Longest Common Subsequence (2D State)
Coin Change uses a one-dimensional state. The moment you need to compare two sequences, the state grows a dimension. Longest Common Subsequence (LeetCode 1143) is the cleanest way to see that jump, and it shows up constantly in interviews as edit distance, diff tools, and DNA matching.
Ask the same two questions. What is the state? dp[i][j] = the length of the longest common subsequence using the first i characters of string a and the first j characters of string b. Two indices now, because the answer depends on where you are in both strings at once.
What is the transition? If the current characters match, they extend the best subsequence found without them, so dp[i][j] = dp[i-1][j-1] + 1. If they do not match, you drop one character from either string and keep the better option, so dp[i][j] = max(dp[i-1][j], dp[i][j-1]).
def longestCommonSubsequence(a, b):
# State: dp[i][j] = LCS length of a[:i] and b[:j]
m, n = len(a), len(b)
dp = [[0] * (n + 1) for _ in range(m + 1)]
for i in range(1, m + 1):
for j in range(1, n + 1):
if a[i - 1] == b[j - 1]:
# Characters match: extend the diagonal state
dp[i][j] = dp[i - 1][j - 1] + 1
else:
# No match: carry the better neighboring state
dp[i][j] = max(dp[i - 1][j], dp[i][j - 1])
return dp[m][n]The base cases are the entire first row and first column set to 0: an empty string shares nothing with any other string. Notice the shape of the work is identical to Coin Change. Define the state, write the transition, set the base cases, fill the table. Only the number of dimensions changed.
Common Mistakes That Tripped Me Up
I want to be honest about the mistakes I made repeatedly before DP clicked. Maybe you'll recognize yourself in some of these.
Jumping to code before defining the state clearly. This was my number one mistake. I'd see a problem, think "okay this is DP," and immediately start writing a recursive function. But I hadn't answered the most basic question: what does dp[i] actually represent? Without that clarity, I'd end up with code that sort of worked for small inputs but fell apart on edge cases. Steven Skiena notes in The Algorithm Design Manual that the hardest part of dynamic programming is formulating the recurrence, not coding it. I learned this the hard way, multiple times.
Choosing a state that stores too much information. On the Longest Increasing Subsequence problem, my first instinct was to track the entire subsequence at each index. That made the state space explode. The fix was realizing I only needed dp[i] = length of the longest increasing subsequence ending at index i. Simpler state, simpler transition, correct solution.
Getting the base case wrong. For the coin change problem, I initially set dp[0] = 1 instead of dp[0] = 0. That off-by-one error cascaded through every single value in my table. I spent 40 minutes debugging the transition when the bug was in the very first cell. Now I write my base cases first and trace through them manually before writing anything else.
Not recognizing when a problem isn't DP at all. I went through a phase where everything looked like a DP problem. Activity selection? I tried DP when a simple greedy (sort by end time, pick non-overlapping) works perfectly. The tell: if you don't need results from subproblems to make the current decision, greedy is probably enough.
Trying to optimize too early. On grid path problems, I'd immediately think about reducing from O(n*m) space to O(n) with a rolling array. But that optimization made debugging nearly impossible. Now I get the straightforward 2D table working first, verify it's correct, then optimize space as a separate step.
The Framework I Use Now
After all those mistakes, I settled on a simple 4-step checklist that I run through every time I see a new problem. It is the same skeleton I reuse across problems, which I put to work in I solved 3 DP problems with the exact same template.
Step 1: Can I break this into overlapping subproblems? If the subproblems don't overlap, it's divide-and-conquer, not DP. Merge sort splits the array into independent halves. That's not DP. Fibonacci calls f(3) multiple times from different branches. That's DP.
Step 2: What's my state? What does dp[i] (or dp[i][j]) actually represent? I write this down in plain English before touching code. "dp[i] = the minimum number of coins needed to make amount i." Clear, specific, testable.
Step 3: What's my transition? How do I compute dp[i] from previously computed states? This is the recurrence relation. For coin change: dp[i] = min(dp[i - coin] + 1) for each coin in my set.
Step 4: What are my base cases? What values do I know without any computation? dp[0] = 0 (zero coins needed to make amount zero). Fill these in first.
Every single DP problem I've solved since follows this framework. It doesn't make DP easy. But it makes DP approachable. I stop staring at the problem hoping for inspiration and start asking structured questions instead.
In upcoming posts on levelop.dev/blog, I'll cover how this framework extends to more complex state definitions. Things like DP on trees (where the state involves subtree structure) and multi-dimensional states and space optimization, where dp[i][j][k] tracks multiple constraints simultaneously. The framework stays the same. The states just get richer.
FAQ
What is dynamic programming and how does it work?
Dynamic programming is a technique for solving complex problems by breaking them into smaller overlapping subproblems, solving each subproblem once, and storing the result so you never recompute it. It works through two core ideas: define a state that captures what you need to know at each step, then define a transition that builds larger solutions from smaller ones. Think of it as smart recursion where you remember every answer you've already calculated.
How do I identify dynamic programming problems in interviews?
Look for three signals: the problem asks for an optimum (minimum cost, maximum profit, longest sequence), it involves counting (number of ways to reach a target), or a brute-force solution would re-solve the same subproblems repeatedly. The strongest indicator is this: if you can define the answer for input of size i in terms of answers for smaller inputs, it's likely a dynamic programming problem.
What is the difference between memoization and tabulation?
Memoization is top-down: you write a recursive solution and cache results as you go, only solving subproblems that actually get called. Tabulation is bottom-up: you fill in an array iteratively starting from the base cases, solving every subproblem in order. Both use the same state and transition logic. The difference is implementation direction, not the underlying thinking.
How do I define states in dynamic programming?
Ask yourself: what is the minimum information I need at step i to make a decision about what comes next? That minimum information becomes your state. Start with a simple 1D state like dp[i]. Only expand to dp[i][j] if the single index genuinely can't capture enough information. For the knapsack problem, you need both the item index and remaining capacity, so dp[i][w] is necessary. But for Fibonacci, dp[i] alone is plenty.
Why is dynamic programming hard for beginners?
Most resources teach DP backwards. They show a finished solution and ask you to memorize the pattern, which feels like magic you could never reproduce on your own. The real difficulty isn't the coding. It's learning to identify states and transitions from a problem description. Once you stop trying to memorize solutions and start practicing the state-plus-transition framework on simple problems, dynamic programming goes from impossible to methodical.