Memoization: Turning Recursion Into Dynamic Programming
The first time I really understood dynamic programming, it was not from a lecture on optimal substructure. It was from watching a slow recursive function get fast after I added four lines of code. That moment is the whole point of memoization, and it is the cleanest on-ramp to DP that I know.
Most people meet dynamic programming as a wall of two-dimensional tables. Memoization comes at it from the other side. You write the obvious recursion first, notice it recomputes the same work over and over, and you cache the results. The recursion does not change. You just stop throwing away answers you already paid for. These dynamic programming problems become approachable once you see that.
What is memoization?
Memoization is a technique where you store the result of an expensive function call and return the stored result when the same inputs show up again. The word comes from "memo," as in a note to yourself. The function leaves itself a note that says the answer for a given input, and it reads that note instead of recomputing.
Two conditions make memoization safe and useful. First, the function has to be pure for the inputs you cache on, meaning the same inputs always produce the same output. Second, the function has to be called with the same inputs more than once, otherwise the cache never gets a hit and you only added overhead. Recursive problems with overlapping subproblems hit both conditions constantly, which is exactly why memoization and recursion fit together so well.
The problem: recursion that forgets
Start with the classic example. The naive recursive function for the Fibonacci sequence is correct and readable, and it is also catastrophically slow.
def fib(n):
if n < 2:
return n
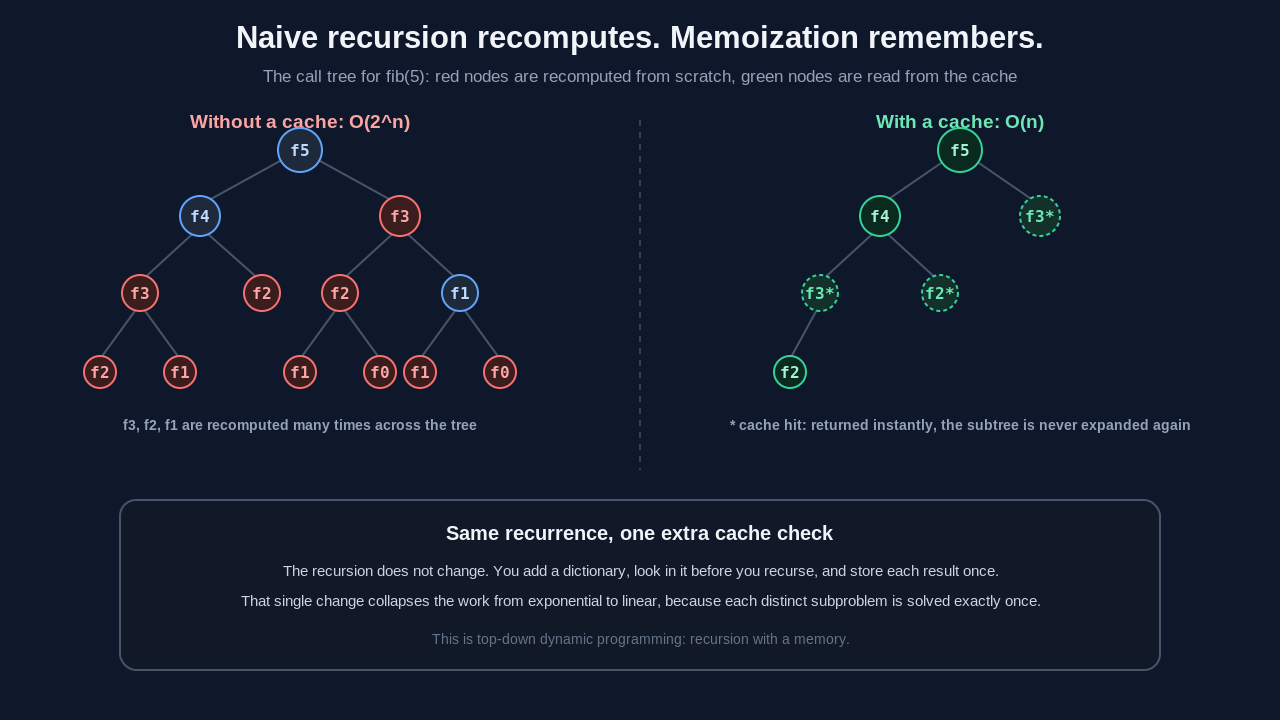
return fib(n - 1) + fib(n - 2)To compute fib(50), this function makes more than 40 billion calls. The reason is that it has no memory. Computing fib(50) calls fib(49) and fib(48). Computing fib(49) also calls fib(48). That second fib(48) redoes the entire subtree of work the first one already finished. The same recursive calls for fib(10) get repeated millions of times across the call tree.
The time complexity is roughly O(2^n) because the call tree branches twice at every level. Every recomputed subtree is pure waste. The answer for fib(48) does not change between the first call and the millionth, so there is no reason to compute it twice.
Adding the cache: memoization in three steps
Here is the part that felt like a magic trick the first time. You do not rewrite the algorithm. You wrap it with a memory.
Step 1: keep the recursive shape
The recursive structure is already correct. fib(n) depends on fib(n-1) and fib(n-2), with a base case at n below 2. Keep that exactly as it is. The recursion describes the relationship between a problem and its subproblems, and that relationship is what we want.
Step 2: add a cache keyed by the arguments
Create a dictionary that maps the input to its computed result. The key is whatever uniquely identifies a subproblem. For Fibonacci that is just n, so an integer key is enough.
Step 3: check the cache before you recurse
Before doing any work, look in the cache. If the answer is there, return it immediately. If it is not, compute it the normal recursive way, store it, then return it.
def fib(n, cache=None):
if cache is None:
cache = {}
if n < 2:
return n
if n in cache:
return cache[n]
cache[n] = fib(n - 1, cache) + fib(n - 2, cache)
return cache[n]That is it. The same recurrence, plus a cache check at the top and a cache write at the bottom. fib(50) now runs in a blink. Each value from fib(2) up to fib(50) gets computed exactly once and read from the cache every time after. The time complexity collapses from O(2^n) to O(n), because there are only n distinct subproblems and each is solved a single time.
In Python you can get the same effect for free with the standard library, which is what you would reach for in production rather than hand-rolling a dictionary.
from functools import lru_cache
@lru_cache(maxsize=None)
def fib(n):
if n < 2:
return n
return fib(n - 1) + fib(n - 2)Why this is already dynamic programming
Here is the claim that reframes the whole topic: the memoized function above is dynamic programming. Not a precursor to it, not a simpler cousin of it. It is the top-down approach to DP, the top-down form.
Dynamic programming has exactly two requirements. The problem must have optimal substructure, meaning the answer to a problem can be built from the answers to smaller subproblems. And it must have overlapping subproblems, meaning those smaller subproblems repeat. Fibonacci has both. So does almost every DP problem you will see in an interview.
When you write the recurrence and add a cache, you have satisfied both requirements directly. The recurrence captures the optimal substructure. The cache exploits the overlapping subproblems. That is the entire definition of dynamic programming, expressed as recursion with a memory. This is why I tell people that if you can write the brute-force recursion and spot the repeated calls, you already know how to do DP. The table-filling version is just a different way to organize the same computation.
Memoization vs tabulation
Once you accept that memoization is top-down DP, the natural next question is memoization vs tabulation. Tabulation is the bottom-up form. Instead of starting from the big problem and recursing down to base cases, you start from the base cases and build up to the answer with a loop and an array.
Here is Fibonacci written bottom-up:
def fib(n):
if n < 2:
return n
dp = [0] * (n + 1)
dp[1] = 1
for i in range(2, n + 1):
dp[i] = dp[i - 1] + dp[i - 2]
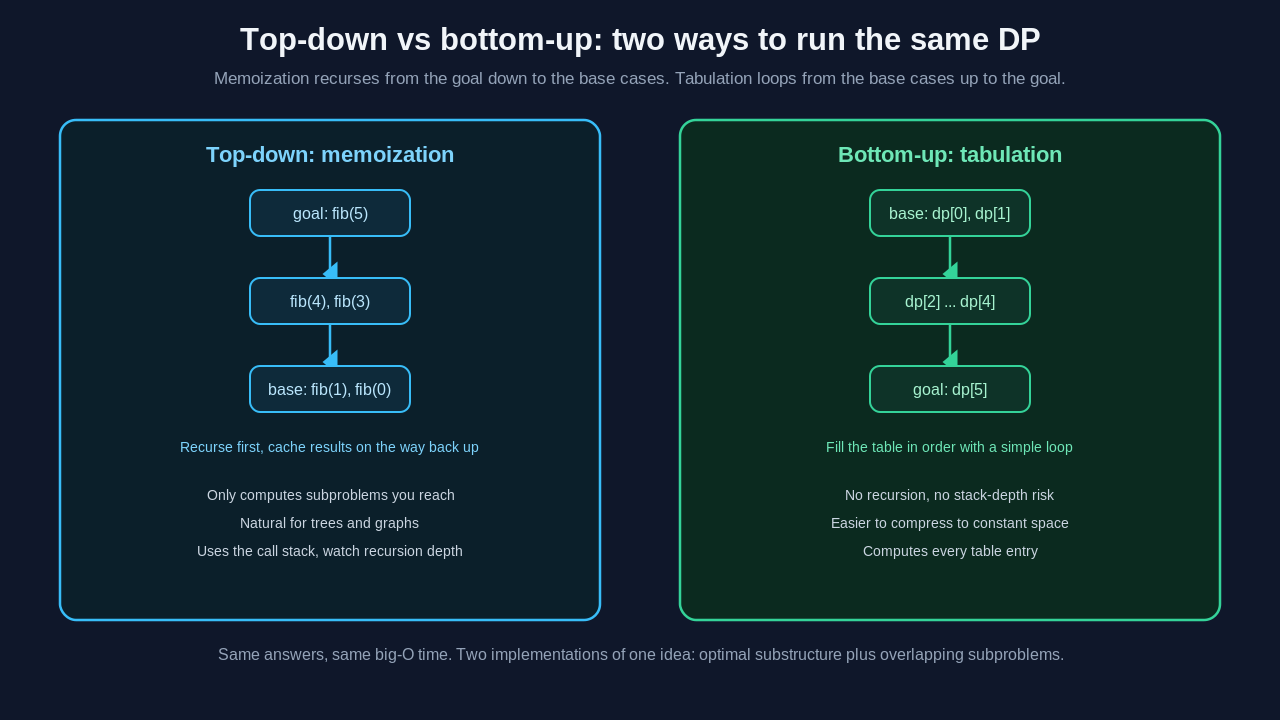
return dp[n]Same answer, same O(n) time, no recursion. You fill dp[2], then dp[3], and so on, each one using values you already computed. This is the top down vs bottom up dynamic programming distinction in one example. The top-down approach, memoization, recurses from the goal toward the base cases and caches along the way. Bottom-up tabulation iterates from the base cases toward the goal.
The two approaches differ in a few practical ways:
- Memoization only computes the subproblems you actually need, because it is driven by the recursion reaching them. Tabulation computes every entry in the table whether or not the final answer depends on it.
- Memoization uses the call stack, so very deep recursion can hit a stack overflow. Tabulation uses an explicit loop and avoids that risk.
- Memoization is usually faster to write because it follows the recurrence directly. Tabulation often makes it easier to optimize space, since you can frequently drop the full table and keep only the last few values.
When memoization wins, and when tabulation wins
Reach for memoization first when the recurrence is easy to write but the iteration order is awkward to reason about. Tree problems and graph traversals are good examples, because the natural way to express them is recursive and the dependency order is not a simple left-to-right sweep. Memoization lets you write the obvious DFS and add a cache without untangling the order yourself.
Reach for tabulation when you need tight control over memory or you are worried about recursion depth. If the subproblem graph is a clean grid and you can see the fill order, the bottom-up loop is often shorter and lets you compress the table down to constant extra space. Many one-dimensional DP problems, including Fibonacci, can keep just two variables instead of a full array once you write them bottom-up.
A real example: DFS plus memoization on a grid
Fibonacci is a teaching example. Here is a pattern that shows up in real interviews: counting unique paths through a grid where you can only move right or down. The recursive shape is a depth-first search from the top-left cell. Each cell's path count is the sum of the path counts of the cell below it and the cell to its right.
def unique_paths(m, n):
cache = {}
def dfs(r, c):
if r == m - 1 and c == n - 1:
return 1
if r >= m or c >= n:
return 0
if (r, c) in cache:
return cache[(r, c)]
cache[(r, c)] = dfs(r + 1, c) + dfs(r, c + 1)
return cache[(r, c)]
return dfs(0, 0)Without the cache, this DFS is exponential, because most cells get reached through many different paths and recompute their entire subtree each time. With the cache keyed on the coordinate pair, every cell is solved once and the whole thing runs in O(m times n). The key insight is the same as Fibonacci, just with a two-part key. The subproblem is identified by the cell coordinates, so the cache is keyed by the coordinate tuple. That is the DFS plus memoization to top-down DP transformation that the title of this post is about, and it generalizes to a huge family of grid and graph problems.
Common mistakes to avoid
How this fits the broader DP pattern
If you want to go deeper, I have written companion pieces on the surrounding ideas. Start with the dynamic programming fundamentals if state and transition still feel fuzzy, then look at how the same template solves a family of DP problems, and finally see how the recursion-meets-cache idea extends to DP on trees where the subproblems live at each node. For more pattern walkthroughs like this one, the full library lives on the Levelop blog.
The takeaway I want you to leave with is simple. You do not need to fear dynamic programming. Write the honest recursion, find the repeated work, and give the function a memory. That is memoization, and that is most of DP.
Frequently asked questions
What is memoization in simple terms?
Memoization is storing the result of a function call so that the next time the function is called with the same inputs, it returns the saved result instead of recomputing it. It is a cache attached to a function, and it is most useful for recursive problems where the same subproblems come up repeatedly.
Is memoization the same as dynamic programming?
Memoization is one of the two standard ways to implement dynamic programming. It is the top-down form, where you write the recurrence as recursion and cache the results. The other form is tabulation, the bottom-up version that fills a table with a loop. Both compute the same answers, so memoization is dynamic programming, just expressed through recursion rather than iteration.
Memoization vs tabulation: which is better?
Neither is universally better. Memoization is usually faster to write and only computes the subproblems you actually reach, which helps when the recurrence is natural but the fill order is awkward, such as in tree and graph problems. Tabulation avoids recursion depth limits and often makes space optimization easier, which helps on large grid or sequence problems. In interviews, writing the memoized version first and mentioning the tabulated alternative shows the strongest understanding.
When should you not use memoization?
Avoid it when subproblems do not repeat, since the cache adds memory and lookup cost with no payoff. Be careful when the input space is enormous, because the cache can grow large enough to become the bottleneck. And watch recursion depth, since deeply recursive memoized functions can overflow the call stack, in which case a bottom-up tabulation approach is the safer choice.
Where to go next
These ideas connect across the DP cluster. Brush up on dynamic programming fundamentals, see the repeatable DP template, and extend the pattern to DP on trees. For more, visit the Levelop blog or the Levelop home page.