
Monolith to Microservices: When and How to Split
I've been breaking down system design concepts that gave me trouble until I worked through them hands-on. This time it's not a coding pattern. It's the scariest architecture question most engineering teams face: "OK, we've decided our monolith needs to split. Now what?"
The Moment You Know It's Time
I wrote previously about how to decide between a modular monolith and microservices. That post covered the decision framework. But it skipped the hardest part: what do you actually do after you decide to migrate?
The decision itself is maybe 5% of the work. The other 95% is figuring out what to extract first and how to route traffic without downtime. You also need to handle the shared database that every module touches. Nobody warns you about that ratio.
Any real microservices migration strategy starts with understanding what signals tell you the monolithic application has outgrown its architecture.
Most teams hit a similar set of pain signals before they seriously consider migrating. These are measurable problems, not hypothetical ones.
Deploy queues that block unrelated teams
Three teams wait on each other to merge because they share a deployment pipeline. You pay a coordination tax on every release. If your deploy queue regularly backs up past two days, that's a clear signal to decompose the monolith.
Build times past 20 minutes
This one creeps up on you. A 5-minute build becomes 10, then 15, then 20. By the time it hits 25 minutes, developers lose the feedback loop entirely.
They start batching changes instead of iterating. Quality drops fast.
Scaling the entire app to serve one hot path
Your image processing pipeline needs 4x the compute of your API layer. But you scale the whole monolith because they share a process. You burn money every month on resources that sit idle. That's a concrete signal, not a guess about future needs.
Outages that cascade across unrelated features
Your payment retry logic has a bug that causes a memory leak. Because it shares a process with your user profile service, profiles go down too. This is the signal that usually triggers the migration conversation at the executive level, because it hits revenue.
What to Extract First
This is where most teams stumble. The instinct is to start with the core domain. Payment processing. Order management. The complex stuff.
That instinct is wrong.
Start with something boring. Pick a module at the edge of your system that has minimal data dependencies and clear input/output boundaries. Here's a practical microservices migration strategy for picking your first extraction target.
The DICE Framework
I didn't invent this name, but I use the framework constantly. Score each candidate service on four dimensions:
D (Data Independence): Does this module own its own data, or does it read from 15 different tables? If it touches shared tables extensively, extracting it means solving the shared database problem before you've even proven the approach works.
I (Interface Clarity): Can you describe the module's API in under 5 endpoints? If the boundary between this module and the rest of the system is fuzzy, you'll spend more time defining the contract than building the service.
C (Change Frequency): How often does this module change relative to the rest of the system? High-change modules benefit most from independent deployment. Extracting something that changes once a quarter gives you almost no value.
E (Error Isolation): If this module crashes, does it take down the rest of the system? Modules with high blast radius are good extraction candidates because isolating their failures protects everything else.
Score each dimension 1 to 5. Start with the candidate that scores highest overall. In practice, things like notification services, image processing pipelines, and search indexers tend to score well.
# Simple DICE scoring for migration candidates
candidates = {
"notification-service": {"data_independence": 4, "interface_clarity": 5, "change_frequency": 4, "error_isolation": 3},
"payment-processing": {"data_independence": 2, "interface_clarity": 3, "change_frequency": 5, "error_isolation": 5},
"search-indexer": {"data_independence": 5, "interface_clarity": 4, "change_frequency": 3, "error_isolation": 4},
"user-profile": {"data_independence": 1, "interface_clarity": 4, "change_frequency": 2, "error_isolation": 2},
}
for name, scores in candidates.items():
total = sum(scores.values())
print(f"{name}: {total}/20")
# Output:
# notification-service: 16/20 <- Start here
# payment-processing: 15/20
# search-indexer: 16/20
# user-profile: 9/20 <- Don't start hereThe notification service and search indexer score highest because they own their data, have clean interfaces, and their failures don't cascade into core business logic. Payment processing scores high on change frequency and error isolation but low on data independence, which makes it a risky first extraction.
The Strangler Fig Pattern: How to Actually Do It
The strangler fig pattern takes its name from a tree that grows around an existing tree and gradually replaces it. The metaphor maps well to software migration and microservice architecture design.
The idea is simple. You don't rewrite the monolithic application. You build new functionality alongside it. Then you gradually redirect traffic from old code paths to new services. The monolith shrinks over time until there's nothing left. Or until you stop because the remaining core works fine as a modular monolith.
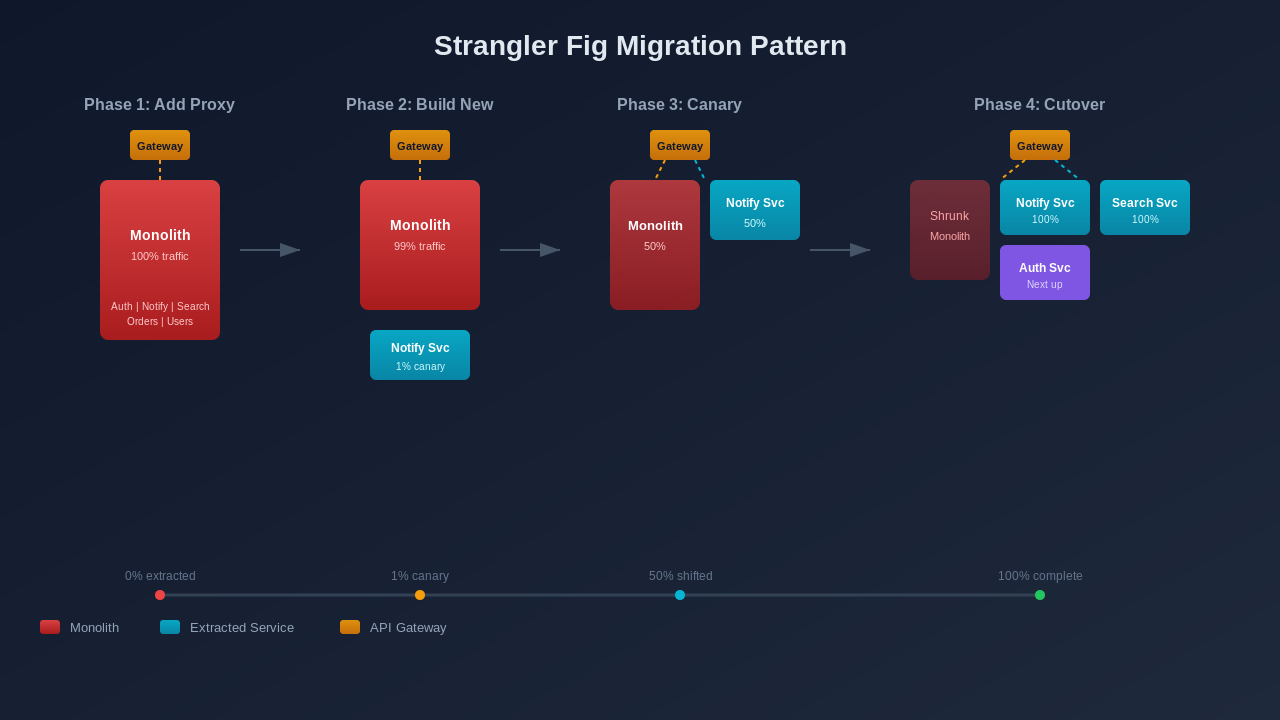
Step 1: Add a routing layer
Before extracting anything, put a reverse proxy or an api gateway in front of the monolith. Every request flows through this layer. Initially, 100% of traffic goes to the monolith. But now you have a control point for the monolith to microservices transition.
# Simplified nginx routing configuration
upstream monolith {
server monolith-app:8080;
}
upstream notification_service {
server notifications:3000;
}
server {
listen 80;
# Phase 1: Route notifications to new service
location /api/notifications {
proxy_pass http://notification_service;
}
# Everything else still goes to the monolith
location / {
proxy_pass http://monolith;
}
}This is the critical infrastructure step. Without it, you can't do gradual migration. You'd have to do a big-bang cutover, and big-bang cutovers fail.
Step 2: Build the new service alongside the old code
Don't delete the old notification code from the monolith yet. Build the new notification service as a separate deployable. Get it to feature parity. Write integration tests that verify both implementations return the same results for the same inputs.
# Verification test: compare monolith and new service responses
import requests
def verify_parity(endpoint, payload):
monolith_response = requests.post(
f"http://monolith:8080{endpoint}",
json=payload
)
new_service_response = requests.post(
f"http://notifications:3000{endpoint}",
json=payload
)
assert monolith_response.status_code == new_service_response.status_code
assert monolith_response.json() == new_service_response.json()
print(f"Parity verified for {endpoint}")Step 3: Canary traffic
Start sending 1% of traffic to the new service. Monitor error rates, latency, and business metrics. If anything looks wrong, you flip back to 100% monolith in seconds. This is the safety net that makes the migration reversible.
Increase gradually: 1% for a day, then 5%, then 25%, then 50%, then 100%. Each step should run for at least 24 hours to catch edge cases that only appear under real load patterns.
Step 4: Cut over and remove dead code
Once the new service handles 100% of traffic for a full week without issues, remove the old notification code from the monolith. This is important. Dead code in the monolith confuses future developers and adds to build times. Clean it up.
The Database Problem (The Hardest Part)
Every migration guide glosses over this. They shouldn't. The shared database is the single hardest problem in monolith-to-microservices migration.
In a monolith, everything reads from the same database. Your notification module probably joins against the users table, the orders table, and maybe a preferences table. Extracting the notification service means figuring out how it gets that data without direct database access.
Option 1: API calls (simplest, least efficient)
The new notification service calls the monolith's API to get user data and order data whenever it needs them. This works for low-volume scenarios but introduces latency and creates a runtime dependency. If the monolith goes down, notifications stop too.
# Notification service fetching data via API
class NotificationService:
def send_order_confirmation(self, order_id: str):
# Fetch from monolith API instead of direct DB query
order = requests.get(f"http://monolith/api/orders/{order_id}").json()
user = requests.get(f"http://monolith/api/users/{order['user_id']}").json()
self.send_email(
to=user["email"],
subject=f"Order {order_id} confirmed",
body=self.render_template("order_confirmation", order=order, user=user)
)Option 2: Data replication via events (better, more complex)
The monolith publishes events when data changes. The notification service subscribes to those events and maintains its own read-optimized copy of the data it needs. This is eventually consistent, but it removes the runtime dependency.
# Monolith publishes events
def update_user_preferences(user_id, preferences):
db.execute("UPDATE preferences SET ... WHERE user_id = %s", ...)
event_bus.publish("user.preferences.updated", {
"user_id": user_id,
"notification_channel": preferences["notification_channel"],
"timezone": preferences["timezone"]
})
# Notification service consumes events and maintains local state
@event_handler("user.preferences.updated")
def handle_preference_update(event):
local_db.upsert("notification_preferences", {
"user_id": event["user_id"],
"channel": event["notification_channel"],
"timezone": event["timezone"]
})Option 3: Shared database with schema ownership (pragmatic compromise)
Keep the shared database for now, but define clear ownership boundaries. The notification service reads from the users table but never writes to it. The monolith owns user data. Document these rules and enforce them in code reviews.
Purists frown upon this approach, but it works well as a transitional step. You can migrate to full data separation later once the service boundary is stable.
Five Migration Anti-Patterns That Will Burn You
I've seen (and made) all of these mistakes. Knowing them ahead of time would have saved me weeks.
1. The Big Bang Rewrite
"Let's just rewrite the whole thing from scratch." This fails almost every time. You build a moving target because the monolith keeps evolving while you rewrite.
You also lose institutional knowledge baked into the old code. There's a reason that "rewrite" comment in the codebase has been sitting there for four years.
2. Data-Driven Decomposition
Splitting services based on database tables instead of business domains leads nowhere good. You end up with a "Users Service" that handles everything vaguely user-related. Authentication, profile photos, preference management all land in one bucket.
Use business capabilities to drive your service boundaries. Domain-driven design gives you a much better decomposition strategy for your microservice architecture.
3. The Shared Library Trap
Creating a shared library of common models used by all services. One team needed to add a field to the User model shared across 40 services. What should have been a two-hour change took three weeks of coordination. Every service needs its own representation of external data.
4. Premature Event Sourcing
Introducing event sourcing, CQRS, and a message broker before you've extracted your first service. Each of these is complex on its own. Adding them all at once, alongside the migration itself, is a recipe for a project that stalls at month four.
5. Ignoring Operational Readiness
Extracting services before you have centralized logging, distributed tracing, and automated deployment pipelines. You will lose requests in the gap between services and have no way to diagnose it. Observability comes first. Extraction comes second.
A Realistic Timeline
Teams always underestimate how long migration takes. Here's what I've seen in practice for extracting a single, well-scoped service.
- Operational readiness (if not already done): 4 to 8 weeks. This is logging, tracing, CI/CD per service. You do this once.
- Identifying and scoring extraction candidates: 1 to 2 weeks. Use the DICE framework. Get team consensus.
- Building the routing layer: 1 to 2 weeks. API gateway or reverse proxy setup.
- Building the first service to feature parity: 3 to 6 weeks. Depends on complexity.
- Canary rollout and validation: 2 to 4 weeks. Don't rush this.
- Dead code cleanup: 1 week.
Total for first service: roughly 12 to 23 weeks. Yes, three to six months for one service. The second extraction goes faster because the infrastructure exists. Expect 4 to 8 weeks per additional service.
If someone tells you they'll migrate the whole monolith in a quarter, they haven't done this before.
When to Stop Migrating
This is the question nobody asks and everyone should. You don't have to extract everything. Most systems end up as a hybrid: a modular monolith core with a handful of extracted services for the parts that genuinely needed independence.
About 42% of organizations now walk back their microservices adoption. They learned this the hard way. The goal was never "zero monolith." The goal was reducing friction in the monolithic application. Once the friction is gone, stop splitting.
My rule of thumb: stop extracting when the remaining monolith is owned by a single team that deploys on a consistent schedule. That team doesn't need microservices. They need a well-structured monolith.
FAQ
When should I start migrating from a monolith to microservices?
Start when you have measurable pain signals, not theoretical ones. Deploy queues backing up past two days, build times over 20 minutes, scaling the entire app to serve one hot path, and cascading outages across unrelated features are all concrete triggers. If you can't point to specific, quantifiable problems, you probably don't need to migrate yet.
What should I extract first from my monolith?
Start with something boring at the edge of your system. Notification services, image processing pipelines, and search indexers make good first candidates because they tend to own their own data and have clear interfaces. Avoid starting with core domain logic like payments or order management, since those have the most data dependencies.
How long does a monolith to microservices migration take?
The first service extraction typically takes 12 to 23 weeks, including operational readiness setup (logging, tracing, CI/CD), building the service, canary rollout, and cleanup. Subsequent extractions go faster at 4 to 8 weeks each because the infrastructure already exists. Full migration for a large system can take 1 to 2 years.
What is the strangler fig pattern for microservices migration?
The strangler fig pattern lets you migrate incrementally by building new services alongside the existing monolith and gradually routing traffic from old code paths to new ones. You add a routing layer (API gateway), build the new service to feature parity, canary traffic at 1% then gradually increase, and remove old code once the new service handles 100% of traffic. The key benefit is that migration is reversible at every step.
Should I migrate my entire monolith to microservices?
Usually not. Most systems end up as a hybrid: a modular monolith core with a handful of extracted services for parts that genuinely needed independence. Stop extracting when the remaining monolith is owned by a single team deploying on a consistent schedule. The goal is reducing friction, not achieving zero monolith.
I've been working through system design patterns on Levelop, and this migration question came up while studying distributed systems. The pattern breakdowns on Levelop's system design track helped me think through service boundaries more clearly.