
Build a Redis Sorted Set Leaderboard for 100 Million Players
I've been breaking down system design concepts that tripped me up during interview prep. Not the textbook versions. The real "oh, that's how it actually works" moments that clicked after I stopped just memorizing and started building. Check out more posts in this series on the Levelop blog.
I Thought a Leaderboard Was Just a Sorted Query
A few weeks ago I got hit with "design a leaderboard system for an online game" in a mock interview. My first instinct: throw scores into a database, run ORDER BY score DESC, done.
That works fine when you have a thousand players. Maybe even ten thousand.
But the interviewer said 100 million players. Scores updating every second. And then: "How do you get player #847,291's exact rank?"
That's when I realized I had no idea how real time leaderboard systems actually work at scale.
The naive SQL approach has two problems. First, sorting 100 million rows on every query is brutal. Even with an index on score, getting a player's rank means counting how many players have a higher score. That's a full scan.
Second, you need this to be fast. Players expect their rank to update in real time, not after a 3-second database query.
I needed data structures where both "update the score" and "get someone's rank" are O(log n). That data structure exists, and Redis has it built in.
Redis Sorted Sets: The Right Data Structure for Leaderboard System Design
A Redis sorted set is a collection where every member has an associated score. Redis keeps the members in sorted order by score automatically. Under the hood, it uses a skip list combined with a hash table. This gives you O(log n) for inserts, updates, and rank lookups.
The commands that matter for a redis leaderboard are surprisingly simple:
- ZADD adds a member with a score, or updates the score if the member exists.
- ZREVRANK returns the rank of a member in descending order (highest scores first).
- ZREVRANGE returns members in a range of scores by rank.
- ZSCORE returns a member's score.
- ZCARD returns total member count.
Here is a quick Python example using redis-py:
import redis
r = redis.Redis(host='localhost', port=6379)
# Use redis zadd to add or update scores
r.zadd('leaderboard', {'player_42': 1500})
r.zadd('leaderboard', {'player_99': 2300})
r.zadd('leaderboard', {'player_7': 1800})
# Get top 10 highest scores in descending order
top_10 = r.zrevrange('leaderboard', 0, 9, withscores=True)
# Get a specific player's rank and score
rank = r.zrevrank('leaderboard', 'player_42')
score = r.zscore('leaderboard', 'player_42')Five commands handle 90% of leaderboard operations. ZADD is O(log n). ZREVRANK is O(log n). ZREVRANGE is O(log n + m) where m is the range size. ZSCORE is O(1). ZCARD is O(1).
A single Redis instance can handle around 100,000 ZADD operations per second on modern hardware. For most games, that's more than enough write throughput for V1.
From Toy Example to Production Leaderboard System
The code above works, but a production leaderboard system needs more thought around key naming, score updates, and resets.
Key Naming and Score Encoding
Name your keys to reflect the scope and timeframe. Use patterns like leaderboard:global:alltime, leaderboard:global:weekly:2026-W22, or leaderboard:region:na:daily:2026-05-28.
This makes it trivial to implement daily, weekly, and seasonal leaderboards. Each timeframe gets its own redis sorted set.
The Score Tie Problem
When two players have the same score, Redis returns them in lexicographic order by member name. That's arbitrary and not what players expect. Most games break ties by "who got there first."
The trick is encoding the timestamp into the score's decimal portion. The integer part is the actual score. The decimal part is a time-based tiebreaker. If two players both have 1500 points, the one who scored first gets the higher rank.
TTL and Leaderboard Resets
Redis sorted sets don't support per-element TTL. You can't expire individual members. But you can expire the entire key.
For a daily leaderboard, set a TTL on the key. For weekly or seasonal resets, stop writing to the old key and start writing to a new one. The old key expires on its own. No complex migration needed.
Read vs Write Patterns
Most leaderboard reads fall into two categories: "show me the top 100" and "show me my rank."
The top-100 query (highest scores in descending order) hits the same leaderboard data every time. This makes it perfect for caching. Put a CDN or application-level cache in front of it with a 5-10 second TTL.
Individual rank queries are unique per user id, so they always hit Redis. But at O(log n), that's roughly 5 microseconds per query. Redis handles it fine.
Scaling Past One Redis Instance
A single redis sorted set with 100 million members uses about 6GB of memory. That fits easily in a modern server. The sorted set operations are still O(log n), so rank lookups take about 27 comparisons.
The real scaling pressure comes from write throughput. If millions of concurrent games end at the same time (think a battle royale with global events), you might exceed what one Redis instance can handle.
Shard by Game or Region, Not by Player
The temptation is to shard players across Redis instances. Don't.
If player_42 is on shard A and player_99 is on shard B, you can't get a global ranking without querying every shard and merging results.
Instead, shard by a dimension that makes independent leaderboards meaningful. Each instance handles a complete leaderboard for its scope. Regional rankings are fast because they hit a single instance.
For a global leaderboard, you merge the top N from each region. This is manageable if you only need the top 100 or 1000.
The Merge Layer for Global Rankings
If you need a global rank for every player (not just the top N), you have two options.
Option 1: Keep a single large redis sorted set with the global leaderboard. 100M members at 6GB is fine. Use read replicas to distribute read load.
Option 2: Each region maintains its own sorted set. A background job merges top scores into a global sorted set on a schedule. Players see a "global rank updated every 5 minutes" disclaimer.
Option 1 is simpler and works for most cases. Option 2 is only necessary when write throughput to a single instance exceeds 100K writes per second.
The Tricky Parts Nobody Warns You About
These details came up in follow-up questions during mock interviews and matter in production.
Relative Ranking
"You're in the top 3% of players!" This requires both the player's rank and total count. Both ZREVRANK and ZCARD are fast, so computing the percentile is cheap.
Near-Me Leaderboard
Players often want to see who's right above and below them, not just the top 10. Redis handles this with offset-based range queries using ZREVRANGE. Pass a calculated start and end position based on the player's rank. This is O(log n + m) where m is the range size.
Historical Leaderboard Data
Once a seasonal leaderboard ends, you want to keep the leaderboard data for historical queries but don't need it in Redis. Snapshot the sorted set to PostgreSQL or S3 before the key expires. This keeps Redis memory lean while preserving history.
The Complete Architecture
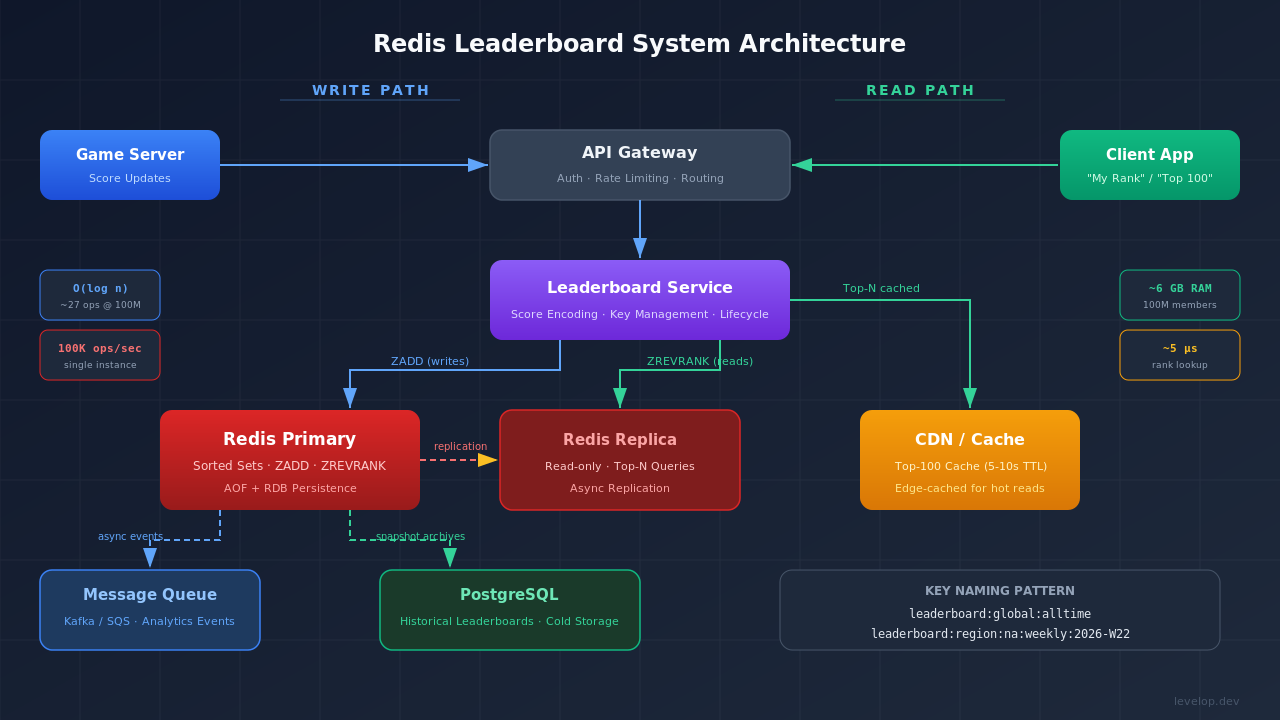
The write path: A game server sends score updates to the leaderboard service API. The service uses ZADD to increment the score on the appropriate redis sorted set (global, regional, daily). An async event goes to a message queue for analytics.
The read path: A client requests "my rank" or "top 100." The leaderboard service checks the cache (for top-N) or calls ZREVRANK/ZREVRANGE on Redis. Results go back to the client.
For persistence, configure Redis with AOF (append-only file). This writes every command to disk. If Redis crashes, you lose at most a few seconds of score updates. RDB snapshots add another safety layer. If you want to understand caching patterns more deeply, check out our guide on caching strategies for system design.
The service layer between clients and Redis handles authentication, rate limiting, and score encoding. It also manages leaderboard lifecycle: creating new weekly leaderboards and archiving expired ones.
What I'd Say in a Leaderboard System Design Interview
If I got this question again, here's how I'd walk through it.
Start with requirements: How many players? How often do score updates happen? What queries do we need (top N, individual rank, near-me)? Real-time or near-real-time?
Then introduce redis sorted sets as the core data structure. Explain why O(log n) for both writes and rank lookups makes it the right choice over a relational database that would need ORDER BY score for every query.
Sketch the single-instance architecture first. Show the key naming scheme, the score encoding trick for ties, and the read/write paths. Then discuss scaling.
Start simple, scale where the bottleneck actually is, and explain why you're making each choice. This is the same principle behind every system design answer. If you're preparing for system design interviews, Levelop has more deep dives on the patterns that actually come up.
Frequently asked questions
Can Redis handle 100 million members in a single sorted set?
Yes. A redis sorted set with 100 million members uses roughly 6GB of memory. ZADD and ZREVRANK operations remain O(log n), meaning about 27 comparisons per operation. A single Redis instance handles 100K+ operations per second on this size dataset.
How do you handle score ties in a Redis leaderboard?
Encode the timestamp into the decimal portion of the score. The integer part is the actual game score. The decimal part is an inverted timestamp so that earlier scores rank higher in ascending order of time. When Redis sees two members with slightly different decimal portions, the earlier submission gets the higher rank.
What happens to a Redis leaderboard when the server restarts?
With AOF persistence enabled, Redis replays the log on startup and recovers all leaderboard data. You lose at most 1-2 seconds of writes depending on your fsync configuration. RDB snapshots provide an additional safety net.
How do you implement a daily or weekly leaderboard reset?
Use separate Redis keys per time period like leaderboard:daily:2026-05-28. Set a TTL on each key so it auto-expires. When a new period starts, your application writes to the new key. No migration needed.
Redis sorted set vs PostgreSQL for leaderboards: when to use which?
Use a redis sorted set when you need real-time rank lookups at scale. ZREVRANK gives you any player's rank in O(log n). In PostgreSQL, getting a rank requires counting rows with higher scores using ORDER BY score, which is slow at scale. Use PostgreSQL for historical leaderboard data, complex queries, and cold storage.