
Redis vs Memcached: When "Just a Cache" Is the Right Answer
Back with another one in the series where I break down the system design concepts I kept getting wrong in interviews. This one cost me an onsite. The interviewer asked me to speed up a read-heavy endpoint, I said "we'll put a cache in front of it," and then they asked the follow-up that ended the round: "Redis or Memcached, and why?" I froze. I knew both were fast in-memory stores. I had no idea how to actually choose between them.
So I went and learned the difference properly. Not the marketing-page version where Redis wins every row of the comparison table, but the real version where Memcached is sometimes the better answer and saying so makes you look like you have actually run these things in production.
The gap I was stuck on
Here is the thing nobody explained cleanly. Redis and Memcached look almost identical from a distance. Both keep data in RAM. Both give you sub-millisecond lookups by key. Both sit between your application and your database to absorb read traffic. If you only ever use them as get(key) and set(key, value), they are interchangeable, and a benchmark on that workload will show them within spitting distance of each other.
So why do two tools exist? My mental model was "Redis is the newer, better one," which is exactly the kind of lazy thinking that gets you eliminated. The real answer is that they were built around different bets about what a cache should be. Three things separate them once you get past get and set: data structures, persistence, and clustering. Understanding those three is the whole game.
What they actually share
Let me start with the common ground, because it is real. Both Redis and Memcached are in-memory key-value stores. Data lives in RAM, so reads and writes are fast in a way disk-backed databases cannot match. Both support setting a time-to-live on a key so entries expire on their own, which is exactly what you want for a cache. Both are battle-tested at enormous scale. Memcached has been holding up Facebook and Wikipedia for well over a decade. Redis runs under a huge fraction of the internet you use every day.
For the simplest possible job, caching the rendered output of an expensive query or an HTML fragment, either one works. If that is genuinely all you need, the differences below might not matter to you, and "just use Memcached" is a perfectly senior answer. Hold onto that thought, because most people forget it.
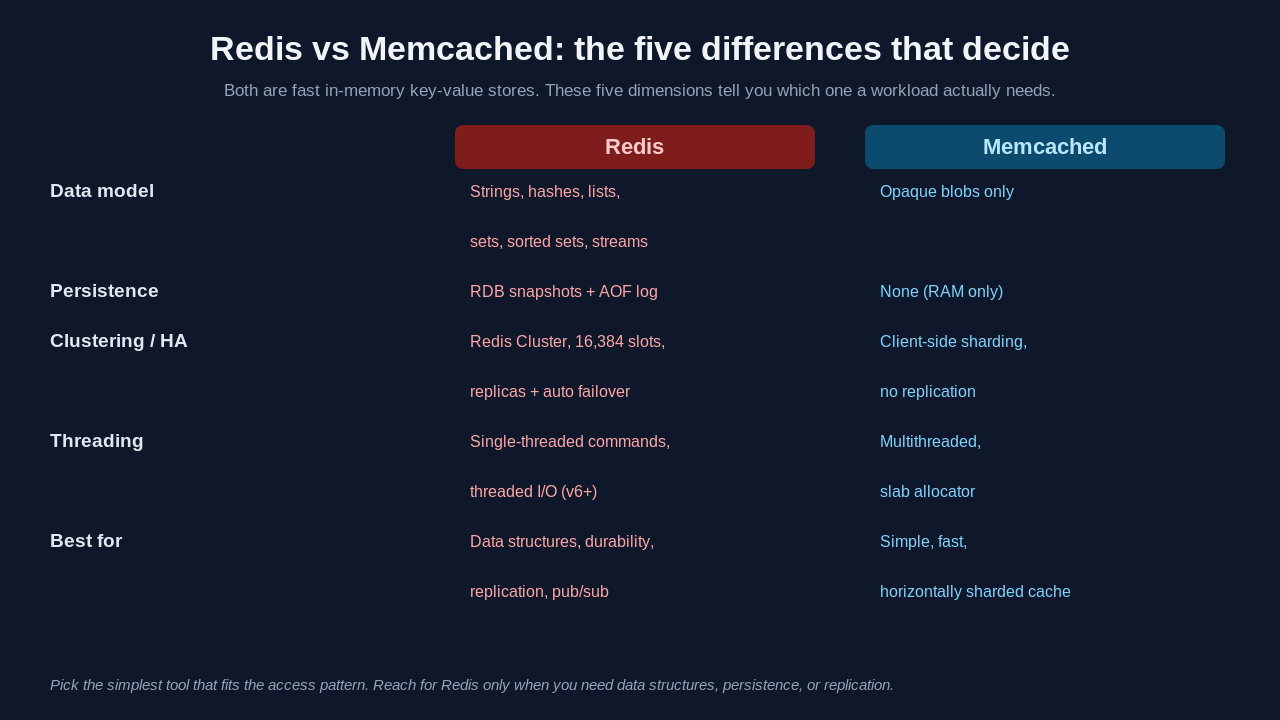
Difference one: data structures
This is the big one. Memcached stores opaque blobs. You hand it a key and a chunk of bytes, and it hands the bytes back later. It does not know or care what is inside. If you want to store a list and append one item, you read the whole list out, deserialize it, append, reserialize, and write the whole thing back. That is a read-modify-write cycle across the network, and under concurrency it is a race condition waiting to happen.
Redis stores data structures. Strings, yes, but also hashes, lists, sets, sorted sets, bitmaps, hyperloglogs, and streams. The operations run inside Redis, on the server, atomically. Appending to a list is one command that touches one structure in place.
The example that made this click for me was a leaderboard. Say you are ranking 100 thousand players by score and you need the top 10 plus each player's rank. In Memcached you would store the whole ranking as a blob and re-sort it on every update, which is absurd. In Redis you use a sorted set:
# Add or update a player's score
r.zadd("leaderboard", {"player:9213": 4820})
# Top 10, highest score first
r.zrevrange("leaderboard", 0, 9, withscores=True)
# A single player's rank
r.zrevrank("leaderboard", "player:9213")The sorted set keeps everything ordered as you write. The top-10 query is a range read, not a sort. That is the difference between a data structure server and a blob cache, and it is why a question like ranking live game scores points straight at Redis.
Difference two: persistence
Memcached holds everything in RAM and nothing else. Restart the process, lose the data. For a cache that is often fine. The cache repopulates from the source of truth as requests come in. A cold cache is a performance problem for a few minutes, not a correctness problem.
Redis can persist to disk. It offers two mechanisms, and knowing both is worth a point in an interview. RDB takes point-in-time snapshots of the dataset at intervals. AOF (append-only file) logs every write operation so the dataset can be rebuilt by replaying the log. You can run either, both, or neither.
# redis.conf, roughly
save 900 1 # RDB snapshot if at least 1 key changed in 900s
appendonly yes # also keep an append-only log
appendfsync everysecHere is the part people get wrong. Persistence does not make Redis a durable database in the way Postgres is durable. With the default appendfsync everysec, a crash can lose up to a second of writes. RDB snapshots can lose minutes. So Redis persistence is excellent for surviving a restart with a warm dataset, and it is risky as the only home for data you genuinely cannot lose. Memcached makes the opposite bet on purpose: it does not pretend to be durable, so you never get confused about what it is.
Difference three: clustering and scaling
When one node is not enough, the two diverge hard.
Memcached scales horizontally with no built-in cluster coordination. You run several independent nodes and your client library decides which node owns each key, usually with consistent hashing. It is simple and it works, but the nodes do not know about each other. There is no replication. If a node dies, the keys it held are gone until they repopulate, and your client just routes around it.
Redis Cluster is a real distributed system. It splits the keyspace into 16,384 hash slots spread across primary nodes, supports replicas for each primary, and can promote a replica automatically when a primary fails. You get replication and failover that Memcached simply does not have. The cost is operational complexity. A Redis Cluster is more moving parts to run, monitor, and reason about than a row of independent Memcached boxes.
There is a quieter difference in how they use a single machine too. Memcached is multithreaded and uses a slab allocator, so it can saturate many cores for a pure key-value workload and its memory behavior is very predictable. Core Redis command execution is single-threaded on an event loop, which keeps those atomic data-structure operations simple to reason about. Redis added threaded I/O in version 6 to spread network work across cores, but the command processing itself is still effectively one thread. For raw multithreaded get/set throughput on a big box, Memcached can genuinely come out ahead.
So when is "just a cache" the right answer
Here is the framing that finally made me comfortable answering the interview question, which is really the question of when to use Redis vs Memcached. Do not start from "which tool is more powerful." Start from "what does this workload actually need."
Reach for Memcached when the job is a straightforward cache and you value operational simplicity and predictable multithreaded throughput. Caching database query results, session blobs, or rendered HTML fragments, where every value is opaque and you never need server-side operations on it, is exactly Memcached's lane. You are saying "I need a fast, simple, horizontally sharded blob cache," and that is a legitimate and senior thing to need.
Reach for Redis when you need any of the three differentiators. You need server-side data structures (leaderboards, queues, rate limiters, sets for deduplication). You need the cache to survive restarts warm via persistence. You need replication and automatic failover so a node death is not a thundering-herd event against your database. You also reach for Redis for things that are not caching at all: pub/sub, streams, distributed locks. The moment your "cache" is doing real work on the data, it stopped being just a cache, and that is your signal.
The trap is treating Redis as the default for everything because it has more features. Features you do not use are not free. They are operational surface area, memory overhead, and a more complex failure model. Choosing the simpler tool that exactly fits the job is the senior move, not the junior one.
A worked decision, end to end
Picture three caching jobs in one product and watch how the choice falls out.
First, caching the result of an expensive product-listing query, keyed by filter parameters, expiring after five minutes. The value is an opaque serialized result set. Nothing operates on it server-side. There is no leaderboard, no ranking, no atomic increment. This is Memcached's job. A row of Memcached nodes with consistent hashing is the simplest thing that works, and simple is the point.
Second, a live leaderboard for an in-game event, top 100 plus every player's own rank, updating constantly. This needs a sorted set and atomic score updates. Memcached would force read-modify-write of the entire ranking on every score change. Redis with ZADD and ZREVRANGE does it in single atomic commands. This is Redis's job, and it is not even close.
Third, a per-user rate limiter, "no more than 100 requests per minute." You need an atomic counter with a TTL. INCR plus EXPIRE in Redis is two atomic commands and you are done. Doing this safely in Memcached means fighting its weaker atomic primitives. Redis again.
Notice that the same system uses both, and the right answer in the interview is not "Redis" or "Memcached," it is "Memcached for the query cache, Redis for the leaderboard and the rate limiter, here is why for each." That answer shows you understand the workloads, which is the entire thing they are testing.
How I would frame it in an interview now
When the cache question comes up, I no longer say "we will add a cache" and stop. I say what I am caching, what the access pattern is, and then I pick. If it is opaque blobs with a TTL and I want simple horizontal scaling, Memcached. If I need data structures, warm persistence, or replication and failover, Redis. Then I name the specific feature that drives the choice. That one extra sentence is the difference between sounding like you read a blog post and sounding like you have run this in production.
If you want to go deeper on where caches sit in a larger design, I wrote up the four core caching strategies and their failure modes, and a separate breakdown of building a real-time leaderboard with Redis that puts the sorted-set pattern to work. Both pair well with this one.
What to practice next
Design a session store and argue both sides, Memcached for simple blob sessions versus Redis if you want sessions to survive a restart. Build a sliding-window rate limiter in Redis using a sorted set and reason about why Memcached struggles with it. Sketch a Redis Cluster with three primaries and three replicas and trace what happens when one primary dies. Take a system you know and list every cache in it, then justify Redis or Memcached for each one out loud. That last drill is the one that actually shows up in interviews.
This problem came from the system design track I have been working through on Levelop, where the caching module forces you to defend the choice instead of hand-waving it.
Frequently Asked Questions
Is Redis always faster than Memcached?
No. For pure multithreaded get/set throughput on a large multi-core machine, Memcached can match or beat Redis because it is multithreaded while core Redis command execution runs on a single thread. Redis pulls ahead when you use its data structures to avoid moving data over the network, not on raw blob throughput.
Can I use Redis as my primary database?
You can, but be careful. Redis persistence (RDB and AOF) is built to recover a warm dataset after a restart, not to give you the durability guarantees of a traditional database. With the common appendfsync everysec setting, a crash can lose up to a second of writes. For data you truly cannot lose, keep a durable system of record and use Redis as a fast layer in front of it.
When should I pick Memcached over Redis?
When the job is a straightforward cache of opaque values with a TTL, you want operational simplicity, and you want predictable multithreaded throughput with easy horizontal sharding. If you never need server-side data structures, persistence, or replication, Memcached gives you exactly what you need with less to operate.
What is the difference between Redis Cluster and Memcached sharding?
Redis Cluster is a coordinated distributed system that splits the keyspace into 16,384 hash slots, supports replicas, and does automatic failover. Memcached sharding is client-side: independent nodes with no replication or coordination, where the client library routes keys, usually via consistent hashing. Redis gives you high availability, Memcached gives you simplicity.
Do Redis and Memcached both support data expiration?
Yes. Both let you set a TTL on keys so cache entries expire on their own, which is core to using either one as a cache. The difference is everything around that TTL: what you can store, whether it survives a restart, and how it behaves when a node fails.
References
- Redis documentation, "Redis persistence" (RDB and AOF), redis.io/docs.
- Redis documentation, "Scale with Redis Cluster" (16,384 hash slots), redis.io/docs.
- Memcached project wiki, "About Memcached" and "ConfiguringServer," github.com/memcached.
- AWS, "Comparing Redis (Valkey) and Memcached," ElastiCache documentation.
- Martin Kleppmann, "Designing Data-Intensive Applications," O'Reilly, 2017.