4 Caching Strategies for System Design
I've been breaking down system design concepts that seemed simple on the surface but turned out to have more depth than I expected. This one stuck with me because I kept getting the same interview feedback about caching strategies system design questions.
Every system design mock I bombed in my first year had the same note: "Your caching story is too shallow." I'd say "put Redis in front of the database" and move on. The interviewer would nod, then ask: "Which caching strategy?" And I'd freeze. I didn't know there were different types of caching. I thought caching was just... caching.
It's not. There are four core caching strategies for system design, and each one makes a different bet about consistency, latency, and what happens when things break. Understanding cache aside, write through, write behind, and read through changed how I approach these questions. Once I understood these caching patterns, my interview answers got dramatically better. Not because I memorized patterns, but because I could finally reason about why one approach fits a problem and another doesn't.
What Caching Strategies Actually Solve in System Design
Before jumping into the four types of caching patterns, it helps to be honest about what caching does. Caching reduces read latency and database load by storing frequently accessed data in a faster storage layer, like a memory cache such as Redis or Memcached. That's it. It doesn't solve write scalability. It doesn't fix a bad data model. It doesn't eliminate consistency problems. In many cases, it creates new ones.
The fundamental tension in every caching strategy is between speed and truth. Your cache is fast because it's a copy. But copies go stale. Every caching pattern is really a different answer to the question: "How much staleness can you tolerate, and who's responsible for keeping things fresh?" This is where cache invalidation strategies become critical.
Two metrics define the landscape. Cache hit ratio tells you how often requests are served from the distributed cache versus the database, directly reducing latency and improving response times. Anything below 80% means your memory cache is burning resources without pulling its weight. The staleness window tells you how long your cache might serve outdated data after the source changes, directly impacting user experience.
With that framing, the four caching strategies start making sense.
Cache-Aside: The Lazy Loading Caching Pattern
Cache aside lazy loading is the caching strategy most developers learn first, and it's probably the one you're using right now without calling it by name.
How Cache-Aside Works
The application manages the distributed cache directly. On a read, the app checks the memory cache first. If the data is there (cache hit), return it immediately with minimal response time. If not (cache miss), read from the database, write the result into the cache, then return it.
On a write operation, the app updates the database and then invalidates (deletes) the cached entry. The next read will miss and repopulate the cache with fresh data. This is one of the simplest cache invalidation strategies available.
def get_user(user_id):
# Check cache first
cached = redis.get(f"user:{user_id}")
if cached:
return json.loads(cached)
# Cache miss: read from DB
user = db.query("SELECT * FROM users WHERE id = %s", user_id)
# Populate cache for next time
redis.setex(f"user:{user_id}", 3600, json.dumps(user))
return user
def update_user(user_id, data):
# Update database first
db.execute("UPDATE users SET ... WHERE id = %s", user_id)
# Invalidate cache
redis.delete(f"user:{user_id}")When Cache-Aside Wins
Cache-aside works best for read-heavy workloads where data access patterns are unpredictable. Since only requested data gets cached, you don't waste memory caching things nobody reads. It's resilient too. If the distributed cache goes down entirely, the application still works because it falls back to database queries. Response times increase, but the system stays functional.
E-commerce product catalogs are a classic example. Millions of products, but only a fraction get viewed frequently. Cache-aside naturally keeps the popular items warm without you having to predict which ones matter, creating a better user experience.
Cache-Aside Failure Modes
The dangerous scenario is cache stampede (also called thundering herd). Picture this: a popular cache entry expires based on time based TTL settings. Suddenly, 500 concurrent requests all miss the memory cache at the same instant. All 500 hit the database for the same row. Your database melts.
The fix is a technique called cache locking. When the first request sees a miss, it sets a short-lived lock key. Subsequent requests see the lock and either wait or serve slightly stale data while the first request repopulates the cache.
There's also a subtler problem: the stale data window. Between updating the database and invalidating the cache, any read will get the old value. In most applications this window is milliseconds and nobody notices. In financial caching systems, those milliseconds matter.
Read-Through Cache: Simplifying Your Caching Pattern
Read-through looks similar to cache aside from the outside, but the responsibility shifts in this caching strategy. Instead of the application managing cache updates, the distributed cache itself handles loading data from the database.
How Read-Through Works
The application only talks to the cache. When there's a miss, the cache layer automatically loads the data from the database, stores it, and returns it. The application never runs database queries directly for read operations, which simplifies code and improves response times.
# With a read-through cache, your application code simplifies to:
def get_user(user_id):
# The cache handles miss logic internally
return cache.get(f"user:{user_id}")
# The cache is configured with a loader function:
# cache.set_loader(lambda key: db.query("SELECT * FROM users WHERE id = %s", key))When Read-Through Wins
The big advantage is a simpler application layer. Every developer on the team reads from the distributed cache using the same interface. Nobody accidentally bypasses the memory cache and hits the database directly. Nobody forgets to populate the cache after a miss. The data loading logic lives in one place.
This matters more than it sounds in large engineering teams. With cache aside, I've seen codebases where some endpoints cached results and others didn't, depending on who wrote the code. Read-through eliminates that inconsistency in your caching strategy.
Read-through pairs well with write-through for caching systems where you want the cache to act as the primary data interface. Microservice architectures and event driven systems benefit here because each service can treat its distributed cache as a consistent data layer, reducing latency across service boundaries.
Read-Through Failure Modes
The distributed cache becomes a single point of failure for read operations. With cache-aside, a cache crash means slower response times from database queries. With read-through, a cache crash can mean broken reads if the application doesn't have a fallback path.
Debugging also gets harder. When data is wrong, you now have to check: is the loader function buggy? Is the cache storing the data correctly? Is the time based TTL evicting things too aggressively? The abstraction saves you time during development but costs you time during incidents.
Write-Through Cache: The Conservative Caching Strategy
This is where we shift from read strategies to write strategies in our caching patterns overview. Among the four types of caching approaches, write-through is the conservative choice, and that's exactly why banks use this caching strategy.
How Write-Through Works
Every write operation goes to the memory cache and the database synchronously, in the same operation. The write only succeeds if both the distributed cache and the database confirm it. This means cache updates happen atomically, and the cache always has the latest data.
def update_user(user_id, data):
# Write to both cache and DB in a single operation
# Cache write happens first, then DB write
# Both must succeed for the operation to complete
cache.put(f"user:{user_id}", data) # internally also writes to DB
# Under the hood, the cache layer does:
# 1. Write to cache
# 2. Write to database
# 3. Return success only if both succeedWhen Write-Through Wins
You get read-after-write consistency. The moment a write operation completes, any subsequent read will see the updated value with near-zero response time. There's no staleness window. No eventual consistency. This dramatically improves user experience for interactive applications.
This caching strategy is critical for user-facing operations where people expect to see their changes immediately. Profile updates, password changes, account settings. If someone changes their email address and then immediately loads their profile page, they need to see the new email. Write-through guarantees it.
Combined with read-through, you get a fully consistent cache layer. The application treats the distributed cache as the source of truth, and the cache keeps the database in sync. The AWS caching patterns whitepaper calls this combination the gold standard for consistency-critical systems.
Write-Through Failure Modes
Write latency doubles. Every write operation now has to succeed in two places before returning. For caching systems with low write volume, this is fine. For systems processing thousands of write operations per second, this becomes a real bottleneck affecting response times.
There's also a waste problem. Write-through populates the memory cache with every written value, even if nobody ever reads it. If you're writing analytics events or log data, you're filling your distributed cache with entries that expire untouched based on time based cache eviction policies.
Write-Behind Cache: The High-Performance Caching Pattern
Write-behind is the aggressive caching strategy. Among all types of caching patterns, it gives you the best write performance, but it asks you to accept a risk that makes most engineers nervous.
How Write-Behind Works
Write operations go to the memory cache immediately and return to the caller. The database update happens later, asynchronously. The cache batches up pending write operations and flushes them to the database on a schedule (every N seconds) or when the batch hits a size threshold. This async approach works well in event driven architectures where eventual consistency is acceptable.
# From the application's perspective:
def increment_score(player_id, points):
# Returns instantly after cache write
cache.put(f"score:{player_id}", new_score)
# DB update happens async, maybe seconds later
# Behind the scenes, the cache layer:
# 1. Writes to cache immediately
# 2. Adds the write to an async queue
# 3. Periodically flushes the queue to the database
# 4. Coalesces multiple writes to same key (only latest value written)When Write-Behind Wins
Gaming leaderboards are the textbook example for this caching strategy. When millions of players are updating scores every second, you cannot write each update to a database synchronously. The database would collapse. Write-behind lets you absorb the write burst in the distributed cache and flush to the database in controlled batches, reducing latency dramatically and maintaining fast response times.
The coalescing feature is a hidden superpower. If a player's score changes 50 times in 10 seconds, write-behind only performs one write operation to the database. That's a 50x reduction in database queries.
Analytics counters, session tracking, real-time bidding. Anything where write volume is extreme and you need the database to eventually have the right answer, but not necessarily right now. The user experience stays snappy because writes return instantly from the memory cache.
Write-Behind Failure Modes
For a gaming leaderboard, losing 10 seconds of score updates is annoying but survivable. For a payment system, losing 10 seconds of transactions is catastrophic. This is why write-behind is never used as a caching strategy for financial data.
There's also an ordering problem. If flushes arrive at the database out of order, you can end up with an older value overwriting a newer one. Robust write-behind implementations use sequence numbers or timestamps to detect and resolve this, but it adds complexity to your caching systems.
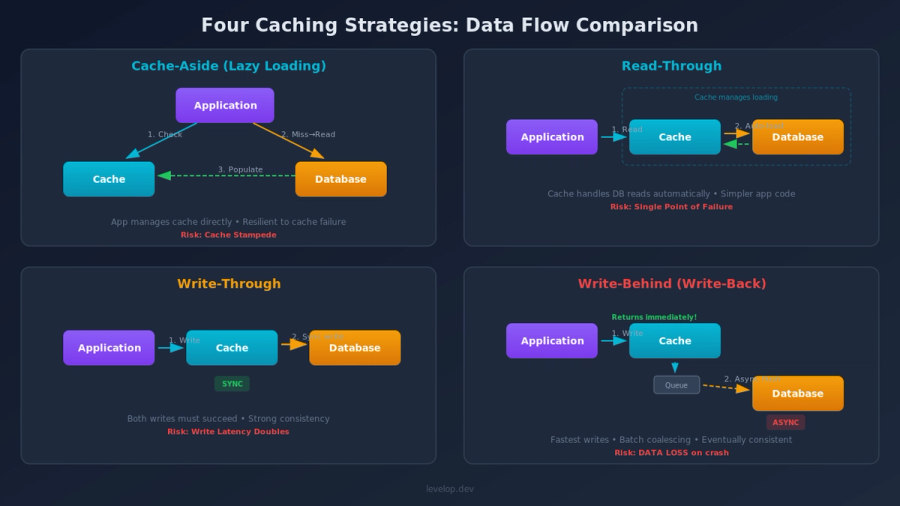
Choosing the Right Caching Strategy for System Design
The choice isn't about which caching pattern is "best." It's about which tradeoff you can live with in your system design. Understanding cache aside write through tradeoffs compared to write-behind helps you make the right call.
Some real-world mappings for these caching strategies:
E-commerce product catalog: Cache-aside with time based cache eviction. Read-heavy, unpredictable access patterns, and a few seconds of staleness is invisible to users while response times stay fast.
Banking account balances: Write-through plus read-through. You need read-after-write consistency and can tolerate higher write latency because write volume is moderate. Strong cache invalidation strategies matter here.
Gaming leaderboard: Write-behind. Write volume is extreme, eventual consistency is fine, and losing a few seconds of data on a crash is acceptable for fast response times and great user experience.
Microservice config store: Read-through with a distributed cache. Every service reads configuration through the cache, and this works especially well in event driven microservice architectures. Clean, consistent interface across dozens of services.
In practice, production caching systems often combine strategies. A common caching pattern is read-through for reads and write-behind for write operations, giving you simplified read logic and high write throughput while reducing latency across the board. Redis supports all four strategies depending on how you configure your client layer.
Caching Patterns for System Design Interviews
If someone asked me today to design caching for a system, I wouldn't start with "let's add Redis." I'd start with three questions about the caching strategy:
- What's the read-to-write ratio? This tells me whether to optimize for read response times or write operations and which types of caching patterns to consider.
- How stale can the data be? This narrows down the consistency requirement and the cache invalidation strategies needed.
- What happens if we lose the distributed cache? This determines the failure tolerance.
From those three answers, the caching strategy usually picks itself. And then I'd name it explicitly: "I'd use a cache aside lazy loading strategy here because the access patterns are unpredictable and we can tolerate 30 seconds of staleness with time based cache eviction." That sentence demonstrates you understand the tradeoff, not just the technology.
The failure mode is the part most candidates skip in system design interviews. Mentioning it unprompted shows the interviewer you've thought about what happens when things go wrong. That's the difference between "put Redis in front of the DB" and actually understanding caching strategies for system design.
Frequently Asked Questions
What is the difference between cache-aside and read-through caching patterns?
In cache aside lazy loading, the application code handles checking the distributed cache, running database queries on a miss, and writing requested data back to the memory cache. In read-through, the cache handles all cache updates internally. The application just calls cache.get(key) and never talks to the database directly. The practical difference is where the data loading logic lives. Cache-aside keeps it in your application code, read-through moves it into the cache layer, which can make response times more consistent.
When should you use write-behind instead of write-through as your caching strategy?
Use write-behind when write volume is so high that synchronous database write operations would create a bottleneck, AND you can tolerate the risk of losing a few seconds of writes if the distributed cache crashes. Gaming leaderboards, real-time analytics, and session tracking are typical examples. Use write-through when you need the guarantee that every write operation is durably stored the moment it completes. Financial caching systems, user authentication, and anything involving money should use write-through with strict cache invalidation strategies.
What happens when a write-behind cache crashes before flushing?
The unflushed write operations are lost. They existed only in the memory cache and hadn't been persisted to the database yet. This is the core tradeoff of write-behind as a caching strategy: you get faster response times for writes in exchange for accepting data loss risk. Mitigation strategies include replication across distributed cache nodes, write-ahead logs, and shorter flush intervals for reducing latency between cache and database sync.
Can you combine multiple caching strategies in system design?
Yes, and production caching systems commonly combine patterns. The most frequent combination is read-through for reads and write-behind for write operations. This gives you a clean read interface with the distributed cache and high write throughput. Another common approach is cache aside write through, using cache-aside for most data and write-through for critical data. The key is matching each data access pattern to the caching strategy that fits its consistency and performance requirements.
What is cache stampede and how do you prevent it in your caching strategy?
Cache stampede (or thundering herd) happens when a popular cache entry expires based on time based eviction and hundreds of concurrent requests simultaneously miss the distributed cache and hit the database, destroying response times. Prevention techniques include cache locking (only one request repopulates while others wait), staggered TTLs (adding random jitter to cache eviction times), and background refresh (repopulating the memory cache slightly before expiration using a background worker).
This concept came from working through system design problems on Levelop, where the interview-focused practice helped me see that caching strategy questions are really tradeoff questions in disguise.