How Edge Caching Delivers Responses in 40ms
I've been breaking down system design concepts that seem simple on the surface. They turn out to have real depth once you start asking questions. This one came up when I was designing a global content platform. I realized I couldn't explain how a CDN actually works beyond "it caches stuff closer to users." Any interviewer wouldn't hold up in a real system design interview.
The Problem Nobody Thinks About Until It's Too Late
Picture this. You deploy your app on a server in Virginia. A user in Tokyo makes a request. That request has to cross the Pacific Ocean, hit your server, get processed, and travel back. That's roughly 12,000 miles round trip.
Even at the speed of light, that's about 65 milliseconds just for the network transit. Add in DNS resolution, TCP handshake, TLS negotiation, and actual server processing time. You're looking at 200-400ms minimum. That's terrible for load times.
For a static image or a CSS file, that's wasteful. The content hasn't changed in weeks. Why is it making a round trip across the planet every single time?
Edge caching solves this problem. And once you understand how it actually works under the hood (edge servers, origin shielding, cache invalidation, and anycast routing), you realize it's one of the most elegant pieces of infrastructure engineering out there.
Edge Servers and Points of Presence
A CDN operates through a network of edge servers distributed across geographic locations called Points of Presence (PoPs). When Cloudflare says they have 300+ data centers worldwide, they're talking about PoPs. Each PoP contains edge servers that store cached copies of your content.
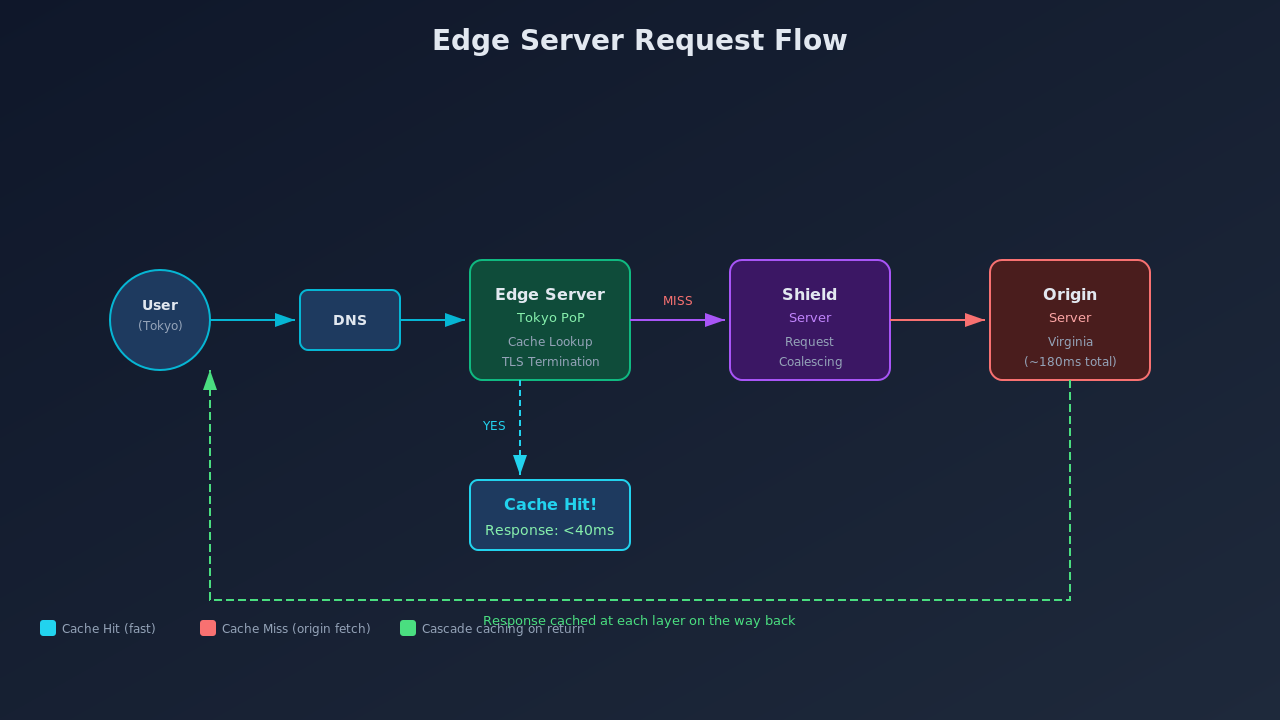
Here's the flow when a user in Tokyo requests an image from your app:
- The request goes to the nearest edge server (Tokyo PoP)
- If the edge server has the image cached (a cache hit), it returns it immediately
- If not (a cache miss), it fetches from the origin server in Virginia, caches it, then returns it
That first user in Tokyo pays the full latency cost. Every user after them gets the response in under 40ms because the content is now sitting in a data center probably 20 miles from them.
The key thing to understand is that edge servers aren't just dumb storage. They make routing decisions, handle TLS termination, and can even run compute (like Cloudflare Workers or AWS Lambda@Edge). But their primary job is serving cached content fast.
Cache Invalidation: The Actually Hard Part
There's a famous quote attributed to Phil Karlton: "There are only two hard things in Computer Science: cache invalidation and naming things." After working through CDN architecture, I get why cache invalidation made the list.
The fundamental tension is this: you want content cached as long as possible (to reduce load on your origin server and improve performance), but you also need updates to reach users quickly. These goals directly conflict.
TTL-Based Expiration
The simplest approach is Time-To-Live (TTL). You set a Cache-Control header on your response:
Cache-Control: public, max-age=86400This tells the edge server to keep this content for 86,400 seconds (24 hours). After that, the next request triggers a fetch from the origin.
TTL works great for content that changes on a predictable schedule. Your company's logo? Set a TTL of 30 days. Your homepage hero image? Maybe 4 hours. API responses with live data? Maybe 60 seconds, or don't cache at all.
The problem with TTL is what happens when you need to update something NOW. You just pushed a fix to a broken JavaScript bundle. The TTL says it's valid for 23 more hours. Every user gets the broken version until the cache expires. That's unacceptable.
Purge-Based Invalidation
This is where purge mechanisms come in. Most CDNs let you explicitly invalidate cached content:
# Cloudflare API example
import requests
response = requests.post(
f"https://api.cloudflare.com/client/v4/zones/{zone_id}/purge_cache",
headers={"Authorization": f"Bearer {api_token}"},
json={"files": ["https://example.com/static/app.js"]}
)You can purge by exact URL, by wildcard pattern, by cache tag, or just nuke everything. But purging has its own problems.
A global CDN might have 300+ PoPs. When you purge, that invalidation needs to propagate to every single one. This isn't instant. There's a window (usually 2-30 seconds depending on the CDN) where some edge servers have the old content and some have already purged it. Users hitting different PoPs see different versions.
Cache Keys and Versioning
A smarter approach is to never invalidate at all. Instead, you change the cache key. If your JavaScript bundle is served at /static/app.js, you change it to /static/app.v2.js or /static/app.abc123.js where abc123 is a content hash.
<!-- Old version (still cached, but nobody requests it anymore) -->
<script src="/static/app.a1b2c3.js"></script>
<!-- New version (cache miss, fetched from origin, then cached) -->
<script src="/static/app.d4e5f6.js"></script>The old version stays in cache until its TTL expires naturally. The new version gets fetched and cached on first request. No purging needed. No consistency window. Every user gets the correct version because the HTML page itself points to the new URL.
This is why tools like Webpack add content hashes to filenames. It's not just for cache busting during development. It's a production cache invalidation strategy.
Origin Shielding: Protecting Your Backend
Here's a scenario that surprised me when I first thought about it. Your origin server is in Virginia. You have 300 PoPs worldwide. A popular image that isn't cached yet gets requested simultaneously from 50 different PoPs. Without any protection, your origin server gets 50 concurrent requests for the exact same file.
Now imagine this happens during a cache purge of your entire CDN. Suddenly hundreds of PoPs are all hitting your origin at once for every piece of content. This is called a thundering herd problem, and it can take down your origin server at the worst possible moment.
Origin shielding solves this by adding a caching layer between the edge servers and the origin.
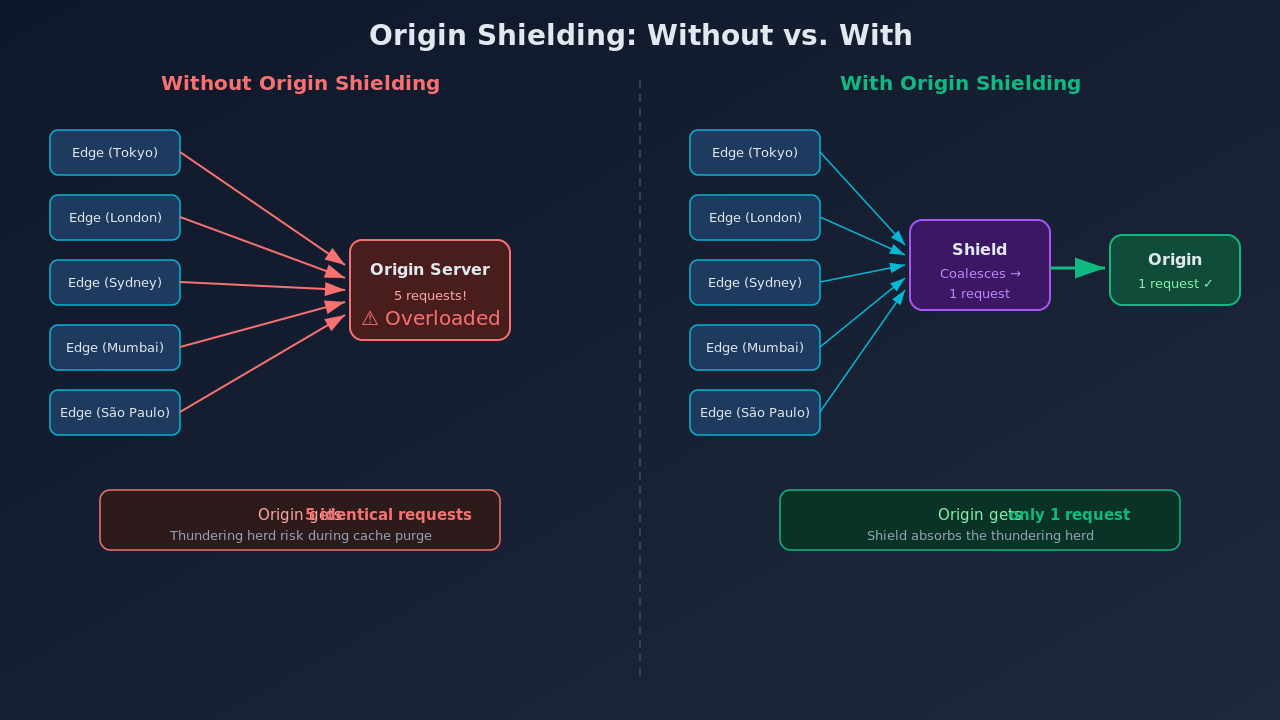
The shield server sits in the same region as your origin. When multiple edge servers need the same content, the shield server collapses those requests into a single origin fetch. It caches the response and distributes it to all the requesting edge servers.
This is a concept called request coalescing. Instead of 50 requests to origin, you get 1. Your origin server barely notices the traffic spike.
Some CDNs let you configure multiple shield locations. If you have edge servers in Asia, Europe, and North America, you might set up shield servers in each region. Asian edges hit the Asian shield, European edges hit the European shield. Only the shields talk to origin.
Anycast Routing: How Users Find the Nearest Edge
Everything I've described so far assumes the user's request magically arrives at the nearest edge server. But how does that actually happen? Your domain resolves to an IP address. How does the same IP address route to Tokyo for one user and London for another?
The answer is anycast routing. In normal unicast routing, one IP address maps to one server. In anycast, the same IP address is announced from multiple locations simultaneously using BGP (Border Gateway Protocol).
When a user's request enters the internet's routing system, BGP routing protocols direct it to the closest network location announcing that IP address. "Closest" here means fewest network hops, not necessarily geographic distance, though they usually correlate.
This is elegant because the client doesn't need to know about any of this. The DNS resolution returns a single IP. The network handles the routing automatically. No client-side logic. No geographic databases. The internet's own routing infrastructure does the work.
Anycast also provides built-in resilience. If a PoP goes down, that location stops announcing the IP via BGP. Traffic automatically routes to the next closest PoP. No DNS TTL to wait for. No health check delays. BGP convergence happens in seconds.
This is also why CDNs are effective at DDoS protection. Attack traffic gets distributed across all PoPs instead of concentrating on a single server. Each PoP absorbs its share of the attack traffic.
Putting It All Together: A Real Request
Let's trace a complete request to see how all four concepts work together.
A user in Mumbai opens your web app. Their browser needs to fetch app.d4e5f6.js.
Step 1: DNS + Anycast. The browser resolves your CDN domain. DNS returns an anycast IP. The user's ISP routes the request to the nearest PoP, which is in Mumbai.
Step 2: Edge server checks cache. The Mumbai edge server looks up the cache key app.d4e5f6.js. It's there, the TTL hasn't expired, and the content hash matches. Cache hit. Response goes back to the user in 12ms.
Now imagine the file was just deployed with a new hash: app.g7h8i9.js.
Step 3: Origin shield. The Mumbai edge doesn't go directly to origin. It routes to the shield server. The shield also doesn't have this file. It forwards the single request to origin.
Step 4: Origin fetch. The origin server in Virginia processes the request, returns the file with appropriate Cache-Control headers.
Step 5: Cascade caching. The shield server caches the response and sends it to the Mumbai edge. The Mumbai edge caches it and returns it to the user. Total time: maybe 180ms for this first request.
Step 6: Subsequent requests. The next user in Mumbai (or anyone routed to the Mumbai PoP) gets it in 12ms.
Meanwhile, if users in London, Tokyo, and São Paulo also request app.g7h8i9.js, their edge servers independently fetch from their respective shield servers, which independently fetch from origin (or share a shield). Each region pays the cold-start cost exactly once.
Common Mistakes in System Design Interviews
When discussing CDN architecture in interviews, I've noticed a few mistakes that come up repeatedly.
Forgetting cache invalidation trade-offs. If you say "we'll use a CDN" without discussing how stale content gets updated, the interviewer will push back. Always mention your invalidation strategy, whether that's versioned URLs, purge APIs, or short TTLs for dynamic content.
Treating CDN as a black box. Saying "the CDN handles it" without explaining edge servers, PoPs, or routing suggests surface-level understanding. Walk through the request flow.
Ignoring the origin thundering herd. When you describe purging a CDN, always follow up with how you protect the origin. Origin shielding or request coalescing is the answer.
Not distinguishing static vs dynamic caching. CDNs cache static assets aggressively. Dynamic content (API responses, personalized pages) requires different strategies: short TTLs, stale-while-revalidate, or edge compute. Don't apply the same caching strategy to both.
What to Explore Next
If this clicked for you, here are some related concepts worth digging into, ordered by how naturally they follow:
- Stale-while-revalidate headers. This lets edge servers return stale content while fetching a fresh copy in the background. It eliminates the latency penalty of cache misses for content that's only slightly outdated.
- Edge compute (Cloudflare Workers, Lambda@Edge). Instead of just caching static files, you can run code at the edge. This opens up personalization, A/B testing, and API routing without round-tripping to origin.
- Multi-tier caching. CDN edge cache, regional shield cache, origin server cache, database. Each tier has different capacity/latency trade-offs.
- Cache warming. Proactively pushing content to edge servers before users request it. Useful for product launches or breaking news.
- Consistent hashing for cache distribution. How CDN nodes decide which cache server stores which content within a PoP.
I've been working through these concepts while building out system design content on Levelop. The CDN design problem is one that connects to almost every other distributed system topic, and it's the kind of thing that shows up in interviews more often than you'd expect.
Frequently asked questions
What is cache invalidation and why is it so difficult?
Cache invalidation is the process of removing or updating stale content from cache servers. It's difficult because you're dealing with distributed systems where hundreds of edge servers worldwide hold copies of your content. Propagating an invalidation across all nodes takes time, creating consistency windows where different users see different versions. The fundamental tension between caching for performance and serving fresh content makes perfect invalidation practically impossible.
How does edge caching reduce latency for global users?
Edge caching stores copies of your content on servers physically close to users. Instead of every request traveling to your origin server (which could be thousands of miles away), the nearest edge server serves the cached response. This reduces latency from hundreds of milliseconds to under 40ms. CDNs maintain networks of Points of Presence (PoPs) in data centers across major cities, so users almost always have a server nearby.
What is origin shielding and when should you use it?
Origin shielding adds a caching layer between edge servers and your origin server. Without it, a cache miss at 300 edge servers means 300 simultaneous requests to your origin. The shield server collapses these into a single request, protecting your backend from traffic spikes, especially during cache purges or viral events. Use origin shielding whenever your origin can't handle the multiplied load of all edge servers requesting content simultaneously.
How does anycast routing work with CDNs?
Anycast allows the same IP address to be announced from multiple geographic locations using BGP routing. When a user makes a request, the internet's routing infrastructure automatically directs it to the nearest PoP announcing that IP address. The user doesn't need to know which server they're connecting to. This also provides automatic failover: if a PoP goes down, BGP stops announcing from that location and traffic reroutes to the next closest PoP within seconds.
What is the difference between cache purging and cache versioning?
Cache purging actively removes content from edge servers, but it takes time to propagate across all PoPs, creating a window where users see different versions. Cache versioning (using content hashes in filenames like app.abc123.js) avoids this by changing the URL itself. The old version stays in cache until it expires naturally, while the new version is fetched fresh. Versioning is generally preferred for static assets because it eliminates consistency issues entirely.