Consistent Hashing Explained: Virtual Nodes and Why They Matter for Distributed Systems
I've been writing about concepts that appear everywhere in system design but rarely get explained well. Consistent hashing is one of those things I thought I understood until someone in an interview asked me about virtual nodes. I could explain the hash ring. I could not explain why a ring with only physical nodes breaks in practice.
The Problem Consistent Hashing Solves
Say you have five cache servers and you need to decide which server stores a given key. The simplest approach: take the hash of the key, mod it by 5, and you have your server index.
server = hash(key) % 5This works fine until a server dies. Now you have four servers. hash(key) % 4 produces a completely different mapping for nearly every key. If you had a million keys cached across those five servers, roughly 80% of your cache lookups will miss after losing just one node. That is not a graceful failure. That is a thundering herd hitting your database.
The same thing happens when you add a server. Scaling from 5 to 6 nodes reshuffles most of your keys. Every scale event becomes a near-total cache invalidation. With horizontal scaling being table stakes for any real world distributed system, this approach falls apart fast when you need to distribute data across multiple servers.
The consistent hashing algorithm solves this by changing how keys map to servers, so that when a node is added or removed, only a small fraction of keys need to move. This minimized data movement is the core reason consistent hashing became the standard approach for distributed systems.
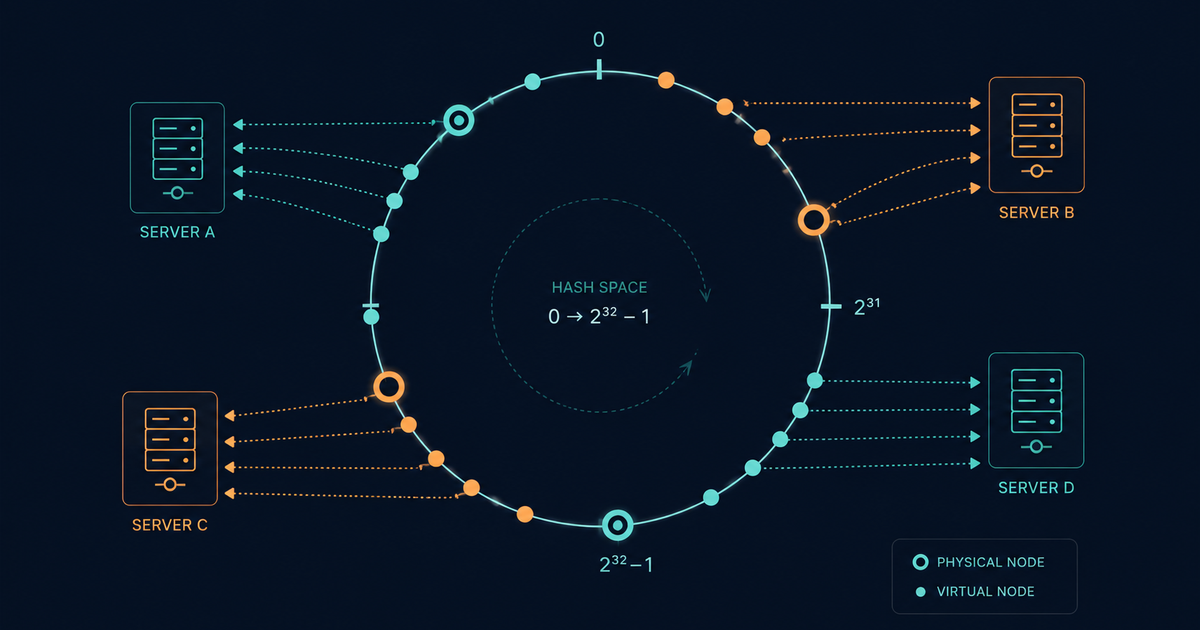
The Hash Ring
Instead of modulo arithmetic, imagine arranging the entire output range of your hash function into a circle. A 32-bit hash gives you a ring from 0 to 2^32 - 1. The top of the ring wraps around back to 0.
Now place each server at a position on this ring by hashing its identifier (like its IP address or hostname). Each server sits at one point on the circle.
To find which server owns a key, hash the key to find its position on the ring, then walk clockwise until you hit the first server. That server is responsible for that key.
import hashlib
import bisect
class HashRing:
def __init__(self):
self.ring = {} # position -> node name
self.sorted_keys = [] # sorted positions on ring
def _hash(self, key: str) -> int:
return int(hashlib.md5(key.encode()).hexdigest(), 16)
def add_node(self, node: str):
pos = self._hash(node)
self.ring[pos] = node
bisect.insort(self.sorted_keys, pos)
def remove_node(self, node: str):
pos = self._hash(node)
del self.ring[pos]
self.sorted_keys.remove(pos)
def get_node(self, key: str) -> str:
if not self.ring:
return None
pos = self._hash(key)
idx = bisect.bisect_right(self.sorted_keys, pos)
if idx == len(self.sorted_keys):
idx = 0 # wrap around
return self.ring[self.sorted_keys[idx]]When a server goes down, only the keys between it and the previous server on the ring need to move. They shift to the next clockwise server. Everything else stays put. If you have N servers, removing one only moves roughly 1/N of the keys.
This is a massive improvement over modulo hashing. When a sixth server is added to a five-node cluster, only about 1/6 of the keys move instead of 5/6.
Where This Breaks Without Virtual Nodes
The hash ring sounds elegant in theory. But when you place only 5 physical servers on a ring with billions of positions, the gaps between servers are almost certainly uneven.
One server might own 40% of the ring. Another might own 5%. You get hotspots. The server owning the largest arc handles far more traffic and stores far more data than the others. This is the load imbalance problem, and it gets worse with fewer nodes.
I tried to convince myself that a good hash function would distribute servers evenly. It does not. With only 5 points on a ring, the variance is huge. I ran a quick simulation once and saw one node handling 3x the load of the lightest node. In production that means one server is on fire while others are barely working.
A second problem emerges during node failure. When a node goes down, its entire portion of the ring moves to a single neighbor. If that neighbor was already handling 30% of the ring, it now handles maybe 50%. One failure causes a second failure. That is a cascade.
Virtual Nodes Fix Both Problems
The fix is surprisingly simple. Instead of placing each physical server at one position on the ring, you place it at many positions. Each position is called a virtual node (or vnode).
If you assign 150 virtual nodes per physical server, a 5-server cluster has 750 points on the ring instead of 5. Those 750 points are spread much more evenly. Each physical server now owns many small arcs scattered around the ring instead of one large arc.
class HashRingWithVnodes:
def __init__(self, num_vnodes=150):
self.num_vnodes = num_vnodes
self.ring = {}
self.sorted_keys = []
def _hash(self, key: str) -> int:
return int(hashlib.md5(key.encode()).hexdigest(), 16)
def add_node(self, node: str):
for i in range(self.num_vnodes):
vnode_key = f"{node}:vnode{i}"
pos = self._hash(vnode_key)
self.ring[pos] = node
bisect.insort(self.sorted_keys, pos)
def remove_node(self, node: str):
for i in range(self.num_vnodes):
vnode_key = f"{node}:vnode{i}"
pos = self._hash(vnode_key)
if pos in self.ring:
del self.ring[pos]
self.sorted_keys.remove(pos)
def get_node(self, key: str) -> str:
if not self.ring:
return None
pos = self._hash(key)
idx = bisect.bisect_right(self.sorted_keys, pos)
if idx == len(self.sorted_keys):
idx = 0
return self.ring[self.sorted_keys[idx]]The implementation barely changes. The only difference is that add_node creates multiple ring positions per server. The lookup logic is identical.
This solves load balancing because with enough virtual nodes, each physical server owns a near-equal share of the ring. The law of large numbers kicks in. 150 random points per server, spread across 5 servers, gives a much more uniform distribution than 5 random points total.
It also solves the cascade problem. When a server goes down, its virtual nodes are scattered around the ring. The keys from each virtual node move to a different physical neighbor. The load of the dead server gets distributed across all surviving servers, not just one.
How Many Virtual Nodes Do You Need?
The number depends on how much imbalance you can tolerate. With 100 virtual nodes per server and 10 physical servers (1000 points on the ring), the standard deviation in load is around 10% of the mean. Most servers handle between 90% and 110% of the ideal fair share.
With 150 to 200 virtual nodes per server, the distribution gets tight enough for most production systems. Cassandra uses 256 virtual nodes per physical node by default. Amazon DynamoDB (as described in the Dynamo paper) uses a similar virtual node approach.
The tradeoff is memory. Each virtual node is an entry in your ring data structure. With 200 vnodes and 100 servers, that is 20,000 entries. For a sorted array lookup, that means a binary search over 20,000 elements, which takes about 15 comparisons. This is negligible for any real workload.
Where Consistent Hashing Is Used in Real Systems
Consistent hashing appears in more places than most people realize. Whenever you need to uniformly distribute load across nodes and handle the case where nodes are added or removed gracefully, you will likely find consistent hashing at the core.
Distributed Caches
Memcached (via client libraries like ketama) and Redis Cluster both use consistent hashing to partition keys across nodes. When a cache node fails, only its keys need to be refetched from the backing store.
Distributed Databases
Apache Cassandra uses consistent hashing with virtual nodes as its primary data partitioning strategy. Each keyspace partition maps to a position on the ring, and vnodes determine which physical server stores it. DynamoDB uses a similar scheme internally.
Content Delivery Networks
CDNs use consistent hashing to decide which edge server caches a given URL. When an edge node goes offline, requests for its URLs are routed to another node, and the rest of the content delivery network is unaffected.
Load Balancers
When you need sticky sessions (where a user's requests always go to the same backend), consistent hashing on the user's IP or session ID achieves this. NGINX supports consistent hashing in its upstream module. Unlike round-robin, consistent hashing preserves session affinity even when backends are added or removed.
Common Mistakes
Too few virtual nodes. Using 10 or 20 virtual nodes per server still produces noticeable imbalance. The minimum for reasonable distribution in a production system is around 100 per server. Start with 150 and adjust based on your observed load distribution.
Forgetting replication. Consistent hashing tells you which node is the primary owner of a key. It does not handle replication. In most distributed systems, you replicate each key to the next N-1 distinct physical nodes clockwise on the ring, skipping duplicate physical nodes from virtual nodes.
What to Explore Next
If consistent hashing clicked for you, explore these related topics: rendezvous hashing (an alternative without a ring structure), the CRUSH algorithm used by Ceph, gossip protocols for membership propagation, and vector clocks for conflict resolution in replicated systems.
This topic came up while I was working through system design problems on Levelop, specifically the distributed cache design.