
Dynamic Programming Patterns: The Core Archetypes
Back with another one in the series where I break down the ideas that took me far too long to understand. This time it is dynamic programming, and the thing nobody told me when I started: most dynamic programming problems are not unique. They fall into a small number of dynamic programming patterns, and once you can name the pattern, the solution stops feeling like a magic trick. If you are grinding dynamic programming patterns for coding interviews, this map is what turns a wall of problems into a short checklist.
For a long time I treated every DP problem as its own puzzle. I would memorize the solution to "house robber," then see "coin change" and feel lost again, as if the first one had taught me nothing. The problem was not the problems. It was that I never stepped back to ask which family each one belonged to. There are really only a handful of types of dynamic programming problems, and that is the whole insight.
The gap I kept falling into
Here is the specific thing that tripped me up. I could follow a DP solution line by line and still have no idea how I would have come up with it. The recurrence always looked obvious in hindsight and impossible in foresight. I would stare at a new problem and think, where does the array even come from, and why is the loop going backwards.
What I was missing was a map. I knew individual solutions but not the shape of the territory. Dynamic programming is not one technique you apply the same way every time. It is a handful of recurring shapes, and each shape has its own way of defining the state and writing the transition. Learn the shapes, and a new problem becomes "oh, this is that kind of problem" instead of a blank page.
What a DP pattern actually is
A DP pattern is a reusable answer to two questions: what is the state, and how does one state depend on smaller ones. The state is the set of values that fully describe a subproblem. The transition is the recurrence that builds a bigger answer from smaller answers you already solved. Every one of these patterns leans on optimal substructure, the property that the best answer to a problem is built from the best answers to its subproblems, an idea formalized in the CLRS textbook. That is the shared backbone underneath all dynamic programming problems.
Almost every dynamic programming pattern is just a different answer to "what does my state look like." Once you see that, the categories below stop being a list to memorize and start being a checklist you run through. I covered the deeper mechanics of writing transitions in an earlier post on state transitions, not memorization, so I will keep the focus here on recognizing which pattern you are even in.
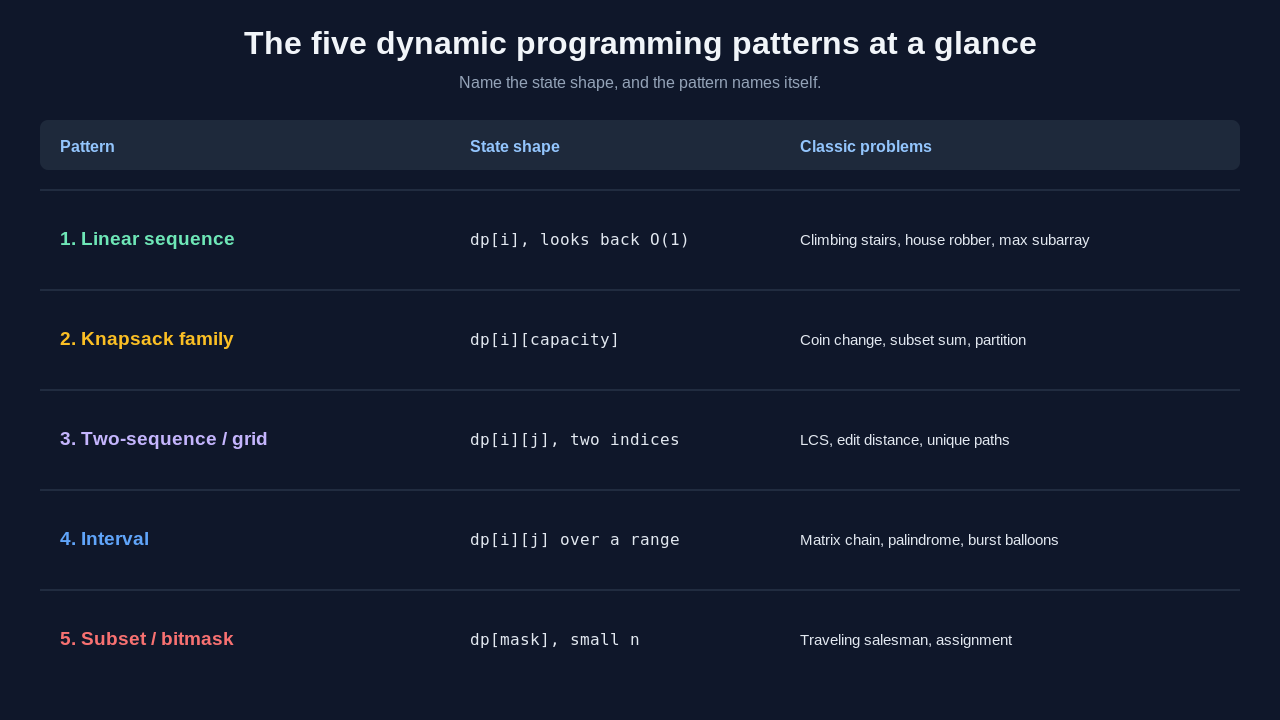
Pattern 1: Linear sequence DP (one dimension)
This is the entry point. The state is a single index into a sequence, and the answer at position i depends on a constant number of earlier positions. Fibonacci, climbing stairs, house robber, and maximum subarray all live here.
The tell is that you are walking along an array making a local decision at each step, and the decision only needs the last one or two results.
def rob(nums):
prev, curr = 0, 0
for x in nums:
# either skip this house (curr) or take it plus everything before the last (prev + x)
prev, curr = curr, max(curr, prev + x)
return currThe state here is "best total using houses up to index i." The transition is one line. No grid, no extra dimensions. If you can phrase a problem as a single pass with a decision that only looks back a fixed distance, you are in this pattern.
Pattern 2: The knapsack family (choosing from items)
The moment a problem says "pick a subset that fits a budget," you are in knapsack territory. The state grows to two dimensions: which items you have considered, and how much capacity or target remains. Subset sum, coin change, partition equal subset, and target sum are all knapsack in disguise.
The split that matters is whether each item can be used once (0/1 knapsack) or unlimited times (unbounded knapsack). That single difference decides the loop direction.
def coin_change(coins, amount):
INF = float('inf')
dp = [0] + [INF] * amount
for coin in coins: # unbounded: each coin reused freely
for a in range(coin, amount + 1):
dp[a] = min(dp[a], dp[a - coin] + 1)
return dp[amount] if dp[amount] != INF else -1The state is "fewest coins to make amount a." Because coins repeat, the inner loop goes forward so a coin can be reused. In 0/1 knapsack you would iterate that inner loop backwards so each item is counted at most once. Getting that loop direction wrong is one of the most common DP bugs, and it is invisible until your answers quietly come out too large. If you want the formal treatment of the knapsack recurrences, cp-algorithms has a clean writeup.
Pattern 3: Two-sequence and grid DP
When the input is two strings or a two dimensional grid, the state usually becomes a pair of indices, one for each sequence. Longest common subsequence, edit distance, and unique paths all share this shape. You are filling a table where cell (i, j) answers a subproblem about the first i of one input and the first j of the other.
def edit_distance(a, b):
m, n = len(a), len(b)
dp = [[0] * (n + 1) for _ in range(m + 1)]
for i in range(m + 1):
for j in range(n + 1):
if i == 0: dp[i][j] = j
elif j == 0: dp[i][j] = i
elif a[i-1] == b[j-1]: dp[i][j] = dp[i-1][j-1]
else: dp[i][j] = 1 + min(dp[i-1][j], dp[i][j-1], dp[i-1][j-1])
return dp[m][n]The state is "cost to turn the first i characters of a into the first j characters of b." Every cell looks at its top, left, and top-left neighbors. Once you recognize the two-index grid, the only real work is deciding what those neighbors mean for your specific problem. Many of these compress from a full grid to two rows, which I dug into in the post on multi-dimensional states and space optimization.
Pattern 4: Interval DP
Interval DP is the one that looks scary and is actually just a different state shape. The state is a range, defined by its two endpoints (i, j), and the answer for a range is built from splitting it at some point k inside. Matrix chain multiplication, burst balloons, and palindrome partitioning live here.
The signature move is a loop over interval length on the outside, then a loop over the split point inside. You build small intervals first because a big interval's answer depends on the smaller intervals it contains.
def lps(s):
n = len(s)
dp = [[0] * n for _ in range(n)]
for i in range(n - 1, -1, -1):
dp[i][i] = 1
for j in range(i + 1, n):
if s[i] == s[j]: dp[i][j] = dp[i+1][j-1] + 2
else: dp[i][j] = max(dp[i+1][j], dp[i][j-1])
return dp[0][n-1]Notice the outer loop runs i from the end backwards. That is not a random choice. A range (i, j) needs the answer for the smaller range (i+1, j-1), so you have to compute shorter ranges before longer ones. Interval DP is where loop order stops being cosmetic and becomes the whole solution.
Pattern 5: DP on subsets (bitmask)
When n is small, usually twenty or fewer, and the problem asks about every possible subset, the state becomes a bitmask. Each bit says whether an element is in the current set. Traveling salesman on a tiny graph, assignment problems, and "can these tasks be partitioned" questions land here.
The state is a bitmask plus maybe one more value, like the current position. The transition flips one bit on as you add an element to the set. It feels exotic the first time, but it is the same idea as the others: a state, and a rule for moving to a slightly bigger state.
There are more shapes beyond these five. DP on trees is its own world, where the state hangs off each node and children roll up into parents. I gave that one a full treatment in DP on trees, and there is a close cousin where recursion plus caching quietly becomes DP, which I wrote about in DFS memoization.
A learning approach that finally worked
Knowing the patterns is half of it. The other half is a way to practice that builds recognition instead of memorization. This is the routine that finally helped me learn dynamic programming for real, instead of just collecting solutions I would forget a week later. Here is the loop I settled on.
First, before writing any code, force yourself to name the state and the transition out loud. If you cannot say "the state is X and it depends on Y," you do not understand the problem yet, and no amount of typing will fix that.
Second, solve problems in small batches, two or three from the same pattern back to back. Doing one house robber problem teaches you a solution. Solving three linear sequence problems in a row teaches you the pattern. The repetition is the point.
Third, when you get stuck, do not jump straight to the editorial. Ask which of the five shapes this could be. Most of the time the question "is this a grid problem or a knapsack problem" unlocks the rest on its own.
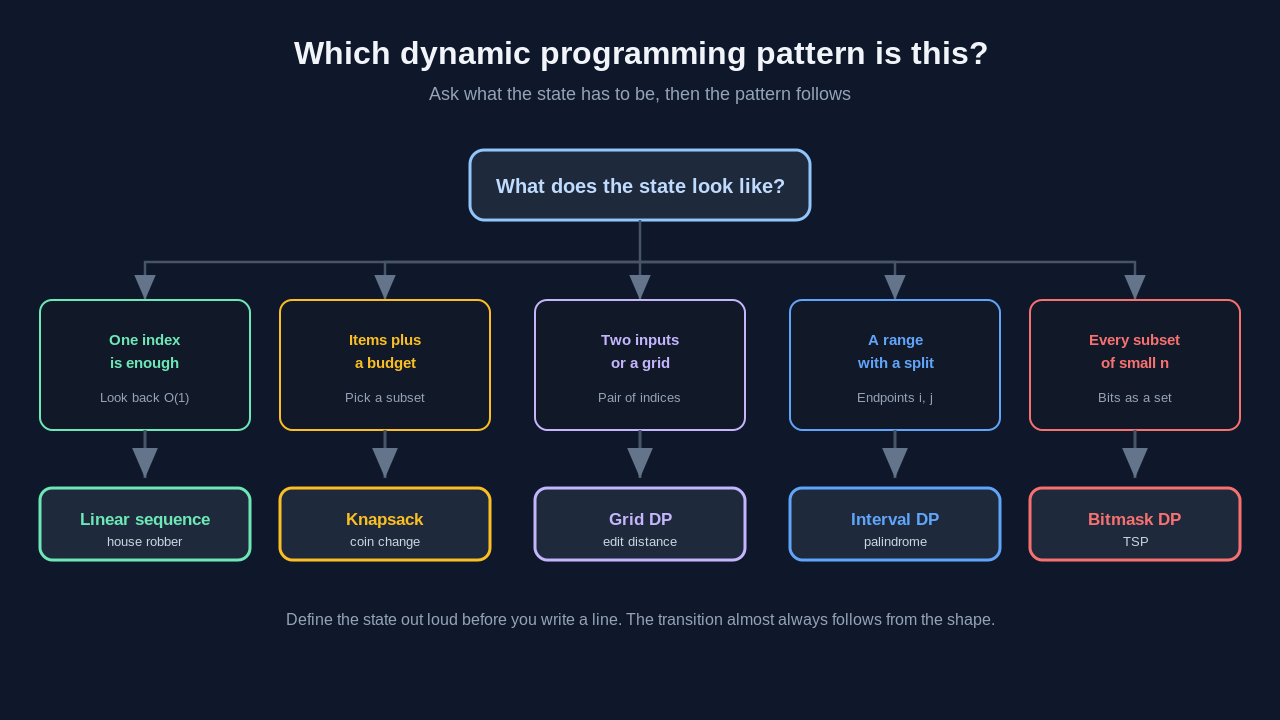
The mistakes I kept making
I want to be honest about what went wrong, because the mistakes taught me more than the wins.
The first was reaching for DP too early. Some problems that look like DP are actually greedy, and a greedy solution is simpler and faster when it applies. I burned a lot of time forcing tables onto problems that did not need them, which is exactly what pushed me to write about when greedy beats DP.
The second was getting the loop direction wrong in knapsack problems. Forward versus backward iteration decides whether items repeat, and I would copy a template without understanding which one I needed. The fix was never copying a loop I could not explain.
The third was defining a state that did not capture enough information. If two different paths reach the same state but should give different answers, your state is missing a dimension. The symptom is a solution that is correct on small inputs and subtly wrong on bigger ones.
What to practice next
If you want to drill these patterns, here is an order that builds naturally. Start with climbing stairs and house robber for linear sequence DP. Move to coin change and partition equal subset for the knapsack family. Then longest common subsequence and edit distance for two-sequence grids. Try longest palindromic subsequence and matrix chain multiplication for interval DP. Finally, attempt a small bitmask problem like the assignment problem once the first four feel comfortable. The LeetCode dynamic programming study plan groups problems in a similar way if you want a ready-made set.
Do them in that order, two or three per pattern, and name the state before you write a line. The goal is not to finish the list. It is to reach the point where a new problem announces its pattern before you have read the second paragraph.
I have been working through problems grouped exactly this way on Levelop, and grouping by pattern instead of by random difficulty is what finally made dynamic programming click for me. You can find more breakdowns like this one on the Levelop blog.
Frequently asked questions
What are the main dynamic programming patterns?
The most common dynamic programming patterns are linear sequence DP (one dimension), the knapsack family (subset selection under a budget), two-sequence and grid DP (two strings or a matrix), interval DP (answers defined over a range with a split point), and DP on subsets using a bitmask. DP on trees is another major shape. Most interview problems map onto one of these.
How do I recognize which DP pattern a problem uses?
Ask what the state needs to be. If a single index is enough, it is linear sequence DP. If you are choosing items against a capacity, it is knapsack. Two inputs usually means a grid. A range with a split point means interval DP. A small n with every subset means a bitmask. The state shape is the fastest way to identify the pattern.
Is dynamic programming still worth learning in 2026?
Yes. Dynamic programming remains a core topic in technical interviews at most major companies and shows up constantly in real systems work like scheduling, resource allocation, and sequence alignment. Reputable curricula such as MIT OpenCourseWare 6.006 and the CLRS textbook still treat it as foundational, and it is not going anywhere.
What is the difference between memoization and tabulation?
Memoization is top down. You write the recursion naturally and cache results so each state is computed once. Tabulation is bottom up. You fill a table from the smallest subproblems toward the answer. They solve the same recurrences. Memoization is often easier to write, while tabulation gives you more control over space and loop order.
How many DP problems should I solve to get comfortable?
There is no magic number, but solving two or three problems per pattern across the main archetypes, roughly fifteen to twenty problems total, is usually enough to start recognizing the shapes on sight. Quality of reflection matters more than raw count. Naming the state and transition for each one is what builds the recognition.
The bottom line
Dynamic programming stops being scary the moment you stop seeing a hundred unique problems and start seeing five recurring shapes. Name the state, match it to a pattern, and the transition usually follows. For the theory behind why these recurrences work, the MIT OpenCourseWare 6.006 lectures are a solid free reference. For more developer breakdowns like this, visit the Levelop blog or explore Levelop to see how we group practice by pattern.