
Agentic Context Engineering for Self-Improving AI Agents
Back with another one in the AI tools series — this time, what happens when you stop hand-curating an agent's context and let the agent curate its own.
I have spent months building agents that run for an hour at a stretch, and I kept hitting the same wall. Early in a run the agent is sharp — it knows the plan, remembers the constraints, makes good calls.
Forty steps later it has forgotten half of what it figured out, repeated a mistake it already solved, and dropped the one instruction that mattered. Every fix I tried was manual — better summaries, tighter prompts, harder pruning — and each worked until it didn't.
That whole problem space has a name now: agentic context engineering. The practice means having an agent build, refine, and maintain its own context over time, rather than treating context as a static thing a human assembles once. If you read my guide to context engineering, this is the next floor up.
There, a human decides what the model sees. Here, the agent decides, using its own execution feedback as the signal. In late 2025 a Stanford, SambaNova, and UC Berkeley team published a framework called ACE that makes the idea concrete, and it is worth understanding even if you never touch their code.
What is agentic context engineering, exactly
Agentic context engineering is the discipline of letting an AI agent evolve its own context — its instructions, strategies, and the knowledge it has gathered — as it works, rather than relying on a fixed prompt or a one-shot human-written setup.
The distinction that matters is who does the curating and when. Classic context engineering is something you do at design time: you choose retrieval strategies, you write the system prompt, you decide what gets compacted.
Agentic context engineering moves that loop inside the running system. The agent attempts a task, observes what happened, reflects on why, and writes the lesson back into a context the next attempt will read. Over many runs, the context stops being a prompt and becomes a working memory.
This is different from fine-tuning. You are not touching model weights. The large language model stays frozen; what changes is the text it reads. That is the appeal: you get behavior that improves with experience, but you keep the audit trail, easy reuse, and zero training cost of a plain context. Andrej Karpathy's framing of context engineering as filling the window with “just the right information for the next step” still holds — the twist is that now the AI system figures out, in near real time, which relevant information earns a place in the window and which does not.
The two failure modes it exists to fix
Before the solution, the two problems that motivated it. If you have built anything that rewrites its own context, you have probably met both.
Brevity bias
The instinct when a context window fills up is to summarize, but summarization is lossy in a biased way: it keeps the gist and throws away the specifics, where the value usually is. The hard-won detail — “this API returns 200 with an error body, so check the payload, not the status” — compresses into “handle errors,” and the agent has no idea what it once knew. Anthropic frames the goal as the smallest set of high-signal tokens; brevity bias is optimizing for small and forgetting high-signal.
Context collapse
The nastier failure is what the ACE researchers named context collapse. When an agent repeatedly rewrites one monolithic context — read it, regenerate the whole thing, overwrite — small distortions compound. Each rewrite is a lossy copy of the last. Run that loop enough times and the context degrades from a detailed playbook into a vague paragraph, sometimes collapsing in a single bad rewrite. Picture the telephone game played by one player against itself.
Iteration 1: 1,800-token playbook, 14 specific strategies
Iteration 5: 1,100 tokens, strategies blurred together
Iteration 9: 380 tokens, generic advice, detail gone
└── context collapseBoth failures share a root cause: treating the context as one blob that gets wholesale rewritten. The fix follows directly from naming that.
The ACE framework: context as an evolving playbook
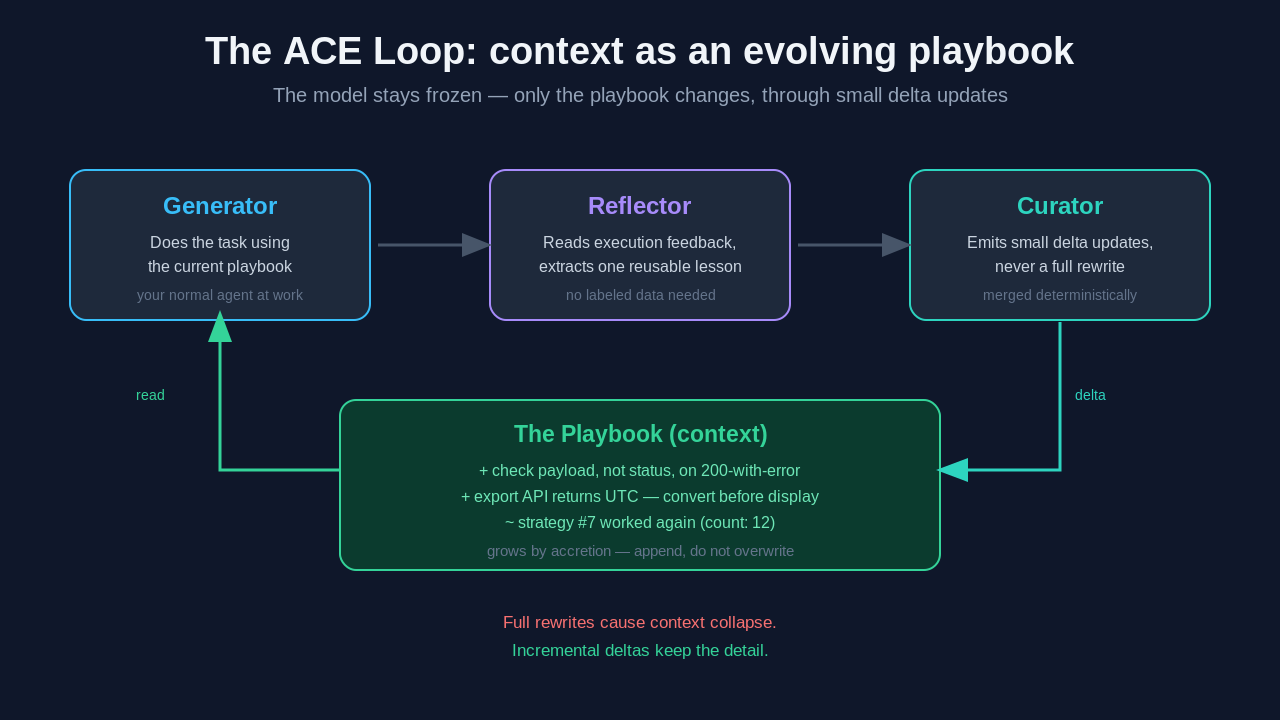
ACE — Agentic Context Engineering — treats the context not as a prompt to be rewritten but as a playbook to be edited incrementally. The paper splits the work across three roles, which you can run as three calls to the same model or as separate components.
Generator, Reflector, Curator
The Generator does the actual task. It takes the current context (the playbook) and produces a response or a trajectory of actions — your normal agent doing normal work.
The Reflector looks at what the Generator did and the feedback that came back — a test result, a failed tool call, a success — and extracts the lesson: a specific, reusable insight, not a summary. It works from natural execution feedback, so you need no labeled training data; the environment's own signals are the supervision.
The Curator decides how that insight enters the playbook. And here is the move that makes the whole thing work: instead of rewriting the context, the Curator produces small structured delta updates — add this bullet, increment a counter on that strategy, mark this one as deprecated. ACE merges these deltas deterministically, and can apply many in parallel. Because nothing rewrites the whole document, there is no telephone-game degradation. The playbook grows by accretion, the way a good runbook does.
# ace_loop.py — the shape of one ACE iteration (model frozen throughout)
def ace_step(playbook, task):
trajectory = generator(playbook, task) # do the task
feedback = environment.evaluate(trajectory) # natural signal: pass/fail/error
insight = reflector(trajectory, feedback) # what to learn, and why
deltas = curator(insight, playbook) # incremental edits, not a rewrite
return apply_deltas(playbook, deltas) # deterministic mergeThis separation of duties is the design's quiet strength. The Reflector can be verbose because its output is consumed, not stored. The Curator is held to small, structured edits because the playbook has to stay coherent over hundreds of iterations — you would not let one function both compute and persist without a boundary between them.
Offline and online: two ways the playbook grows
ACE runs in two modes, and they map onto two real needs.
Offline adaptation is system-prompt optimization. You run the agent against a batch of tasks, let the Reflector and Curator build a playbook, then freeze it and ship it as a better starting context — a system prompt that encodes a hundred runs of experience, none of it written by hand.
Online adaptation is test-time memory: the agent keeps editing its playbook live, learning from each task as it goes. This is the self-improving-in-production version, and where the idea meets the context-management tactics most of us already use.
How it connects to compaction, sub-agents, and memory
If you have read Anthropic's guidance on effective context engineering for agents, the ACE playbook slots neatly alongside three patterns you may already be running. Agentic context engineering is not a replacement for them; it is the layer that decides what they preserve.
Compaction. When a long run approaches the window limit, you summarize and continue. The risk is brevity bias — you compact away the detail. An ACE-style playbook gives compaction a target: keep the playbook, compact the raw trajectory. The durable lessons live in a structure designed to survive, so the summary can be ruthless about everything else.
Sub-agent isolation. Rather than one agent holding state across a whole project, you spin up sub-agents with clean context windows and have them return condensed summaries — Anthropic suggests one to two thousand tokens — instead of full traces. Those summaries are exactly the natural feedback a Reflector consumes: sub-agents generate the signal, the playbook accumulates it. I covered this division of labor in how agentic AI coding tools actually work; ACE is the formal version.
Note-taking and memory. Anthropic's memory tool and the broader “structured note-taking” pattern persist information outside the window and read it back after a reset. That external store is, functionally, the playbook — a durable knowledge base that gives the agent long-term memory beyond the short-term memory of its live context window. ACE's contribution is a disciplined way to write to it: incremental, structured, deterministic, instead of a free-form dump the agent has to re-parse and slowly corrupt.
The honest summary: compaction, sub-agents, and memory are the mechanics you use to manage context at runtime. Agentic context engineering is the policy that decides what flows through them.
Does it actually work?
Skepticism is warranted whenever a framework promises self-improvement, so the numbers matter. On the ACE paper's benchmarks, evolving the context this way produced a +10.6% improvement on agent tasks and +8.6% on a finance reasoning benchmark over strong baselines, and it did so without labeled supervision by leaning on execution feedback alone.
The headline result, reported by VentureBeat, is the AppWorld leaderboard: an ACE-equipped agent on a smaller open-source model matched the top production agent on average and beat it on the harder test-challenge split. The lesson is not that small models are secretly better. Instead, a well-maintained context closes a gap you would otherwise close with a bigger model. InfoQ's writeup agrees: the gains come from context discipline, not scale.
I would still treat the percentages as directional rather than gospel — benchmark deltas rarely transfer cleanly to your real-world workload. But the mechanism is sound, and the failure modes it fixes are real ones I have personally shipped.
When to reach for it, and when not to
Agentic context engineering earns its complexity on long-horizon, repetitive tasks where the agent sees similar situations again and again and execution gives a clean success or failure signal. Coding agents, data-pipeline agents, customer-workflow agents — anything with a feedback loop tighter than a human review cycle. That is where an accumulating playbook pays for itself.
Agentic context engineering is overkill for single-turn features. If your AI does one retrieval and one generation, you want good prompt engineering and plain context engineering, not a Generator-Reflector-Curator loop. Adding a self-editing memory to a stateless feature is pure overhead and a new surface for bugs.
The other caution is governance. A context that rewrites itself is a context you have to monitor. Log the deltas. Diff the playbook between runs. A bad insight, learned confidently from a fluke, will propagate through your agentic systems exactly as efficiently as a good one. Self-improving systems are also self-degrading systems if you stop watching them, because a real-world tool call can mislead the Reflector just as easily as it can teach it.
How to start practicing it
You do not need the full framework to get the benefit. Start here:
# minimal_playbook.py — a starter you can add to any agent
playbook = [] # list of structured, append-only lessons
def record_lesson(trajectory, feedback):
# Reflector: extract ONE specific, reusable insight
lesson = reflect(trajectory, feedback) # e.g. {"strategy": "...", "evidence": "..."}
# Curator: append, never rewrite the whole thing
playbook.append(lesson)
def build_context(base_prompt):
# the playbook rides along with every run
return base_prompt + render_as_bullets(playbook)Three rules carry most of the value. Append, do not overwrite — that single discipline kills context collapse. Make every lesson specific enough to act on; “be careful with dates” is useless, “the export API returns UTC, convert before display” is a real edit. And keep the lessons structured so you can later prune, dedupe, and audit them. Once that loop is earning its keep, the ACE reference implementation is worth a read for how they handle parallel deltas and deduplication at scale.
For the foundational concepts underneath all of this, start with the context engineering guide, and browse the rest of the Levelop blog for the wider AI tools series.
Frequently asked questions
What is agentic context engineering in simple terms?
Agentic context engineering means letting an AI agent build and refine its own context as it works, instead of a human writing a fixed prompt. The agent tries a task, learns from what happened, and writes that lesson into a context the next run will read — so it improves with experience without any model retraining.
How is ACE different from fine-tuning?
Fine-tuning changes the model's weights and needs training infrastructure and labeled data. ACE leaves the model completely frozen and only changes the text it reads — its context. That makes it cheaper, faster to update, fully auditable, and portable across models, at the cost of being limited to what context can express.
What is context collapse?
Context collapse is the degradation that happens when an agent repeatedly rewrites its entire context from scratch. Each lossy rewrite compounds the last, and over many iterations a detailed playbook erodes into vague, generic text. ACE avoids it by applying small incremental delta edits instead of wholesale rewrites.
Do I need the full ACE framework to benefit?
No. The single highest-value idea is delta updates: have your agent append specific, structured lessons to a persistent playbook instead of regenerating its whole memory. You can add that to an existing agent in an afternoon and get most of the protection against context collapse without adopting the Generator-Reflector-Curator split.
Is agentic context engineering the same as giving an agent memory?
Memory is the storage; agentic context engineering is the policy for writing to and reading from it well. A memory tool persists information outside the window, but without discipline it fills with low-signal dumps that the agent slowly corrupts. Agentic context engineering decides what gets written, in what structure, and what survives compaction.
When should I not use it?
Skip it for single-turn or stateless features — one retrieval, one answer. There, plain prompt and context engineering is simpler and sufficient. The self-editing loop only pays off for long-horizon, repetitive tasks with a clear execution feedback signal.
I've been building Levelop to help engineers learn the systems thinking behind modern AI work. A clever prompt gets you one good answer; an agent that maintains its own context is what keeps getting better while it ships.