
Context Engineering vs Prompt Engineering: What Actually Changed in 2026
Another one in the AI tools series. Last time I covered what context engineering is from scratch. This post answers the question I got most in response: how is context engineering vs prompt engineering actually different, and which one should I be learning?
I have a strong opinion here, because I lived the switch. For about a year my entire AI skill set was prompt engineering. I collected clever phrasings, I A/B tested system prompts, I had a Notion page of openers that “worked.” Then the work changed underneath me. The thing I now spend my time on barely involves writing sentences for the model at all. It involves deciding what the model gets to see. That shift, from wording to information, is the whole story of why the field renamed itself in 2026.
The one-sentence difference
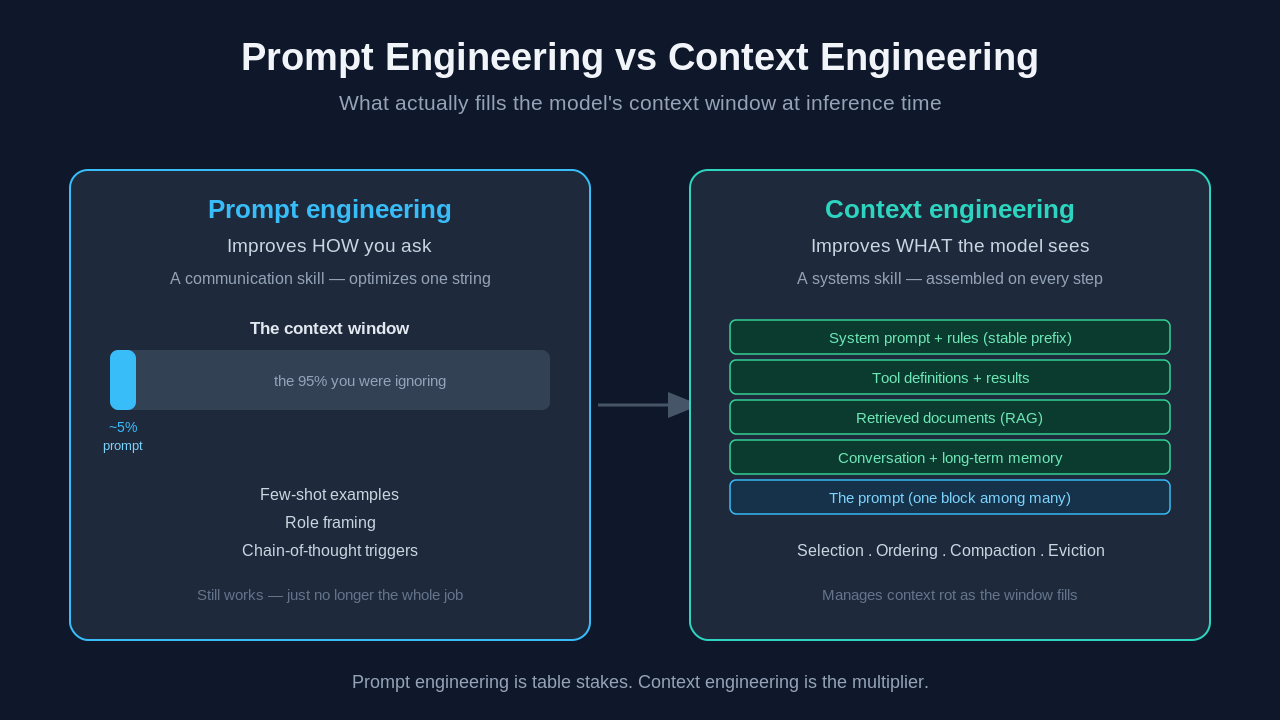
The whole prompt engineering vs context engineering debate collapses into one line: prompt engineering improves how you ask. Context engineering improves what the model has to work with when you ask.
That is the cleanest framing I have found, and it holds up under pressure. Prompt engineering is a communication skill, closer to writing a sharp bug report or a clear spec. Context engineering is a systems skill, closer to memory management, context management, or data pipeline design. One optimizes a string. The other optimizes an entire information environment, deciding which relevant context survives into the window, and it does so continuously, on every step of a task.
If you want the ground-up explanation of the second discipline, I wrote a full guide to what context engineering is. This post assumes you know the basics and want the honest comparison.
Where prompt engineering came from, and what it actually was
Prompt engineering was the first real skill of the LLM era, and it deserves more respect than the “it's dead” crowd gives it. When models were used in single turns, in a chat box, with no tools and no retrieval, the prompt was the entire interface. The difference between “summarize this” and “summarize this in three bullets for a non-technical executive, preserving any numbers” was the difference between useless and useful output. Wording carried all the signal.
So practitioners got good at it. Few-shot examples to show the format you wanted. Role framing to set the register. Chain-of-thought triggers to force reasoning before the answer. Output constraints to get parseable structure. These techniques are real and they still work. None of them have been deleted.
The limitation was never that prompt engineering was wrong. It was that it assumed a world of short, stateless interactions. The moment your application got longer than one turn, or pulled in outside documents, or called a tool, the carefully worded prompt became a small fraction of what the model actually processed.
What broke, and why a new name appeared
The term context engineering settled in June 2025, when Shopify CEO Tobi Lütke and Andrej Karpathy both endorsed it publicly. Lütke described it as “the art of providing all the context for the task to be plausibly solvable by the LLM.” Karpathy agreed on X, pointing out that people associate “prompt” with the short instruction you type day to day, while “in every industrial-strength LLM app, context engineering is the delicate art and science of filling the context window with just the right information for the next step.”
That endorsement gave a name to something builders were already struggling with. Here is what had quietly changed under the hood.
Prompt engineering era Context engineering era
──────────────────── ──────────────────────
single turn multi-step agent loops
no tools dozens of tool calls per task
no memory conversation + long-term memory
prompt = 100% of input prompt = ~5% of input
you write the input a system assembles the inputWhen I instrumented one of my own agents and printed the exact tokens hitting the model, my hand-written prompt was about 5 percent of the window. The other 95 percent was tool outputs, file contents, retrieved documents, and accumulated history. I was obsessing over the 5 percent and ignoring the part that decided whether the run succeeded.
The six dimensions where they actually differ
Vague comparisons are easy. Here are the specific axes where the two disciplines diverge, and where the real work moved.
Scope: one message vs the whole window
Prompt engineering focuses on a single instruction. Context engineering operates on everything in the context window at inference time: system prompt, tool definitions, retrieved chunks, conversation history, tool results, and the user's actual question. The prompt is now one block among many.
Time: static vs continuous
A prompt is written once and reused. Context is assembled fresh on every step, and in an agent loop that can be dozens of times per task. Context engineering is therefore a runtime concern, not an authoring concern. You are not writing text; you are writing the logic that builds text.
Failure mode: bad wording vs context rot
A prompt fails when it is ambiguous. A context fails in a more insidious way. As the window fills, model attention degrades, a phenomenon researchers call context rot. A model with a 200K token window does not treat token 150,000 as carefully as token 500. Prompt engineering has no tool for this. Context engineering exists largely to manage it, through compaction, eviction, and ordering.
Primary lever: phrasing vs selection
The prompt engineer's lever is language. The context engineer's lever is selection: deciding which of the thousands of available tokens earn a place in this specific window. Anthropic's guide to effective context engineering for AI agents frames the best version of this as just-in-time retrieval, giving the model lightweight identifiers (file paths, queries) and letting it pull detail on demand instead of pre-loading everything.
Cost: negligible vs architectural
Prompt wording barely moves your bill. Context decisions dominate it. The Manus team reported that cached tokens cost roughly a tenth of uncached ones, which means whether your context prefix stays byte-for-byte stable across requests is a real budget line. Context engineering is partly cost engineering.
Owner: anyone vs the system designer
Anyone can write a better prompt. Designing what flows into the model across a multi-step task, building the retrieval pipeline, the memory strategy, the tool schemas, is a developer-facing, system-oriented job. This is why “prompt engineer” job posts quietly turned into roles that expect retrieval, memory, and tool design.
Same task, two mindsets
Concrete beats abstract. Say you are building an assistant that answers questions about a large codebase.
The prompt engineering instinct is to write a great instruction and paste in the code:
# Prompt engineering mindset
prompt = f"""You are a senior engineer. Answer accurately and cite files.
Here is the codebase:
{dump_entire_repo()} # 300K tokens, blows the window, mostly irrelevant
Question: {user_question}"""This works on a toy repo and collapses on a real one. The fix is not a better sentence. It is a better information flow:
# Context engineering mindset
context = [
SYSTEM_RULES, # stable prefix, cache-friendly
file_index(), # selection: a map, ~400 tokens
]
tools = [grep_repo, read_file] # model pulls only what it needs
# the model searches, reads 2-3 files, answers
# old tool outputs get evicted as the window fillsSame model, same question. The first approach is a wording problem solved with prose. The second is a systems problem solved with selection, ordering, and eviction. That gap is the entire difference between the two disciplines.
So is prompt engineering dead?
No, and I think the “prompt engineering is dead” headlines get this exactly backwards. Prompt engineering got absorbed, not deleted. It is now one component inside a larger discipline, the way writing a clean function is one component of software architecture. A sloppy system prompt still sabotages everything downstream, no matter how good your retrieval is.
The honest 2026 framing is this: prompt engineering is table stakes, context engineering is the multiplier. Clear instructions are necessary and no longer sufficient. The teams whose AI-generated work actually ships are not the ones with the cleverest prompts. They are the ones who control what the model sees on every step. I made the same argument from the other direction in my breakdown of how agentic AI coding tools work under the hood, where the difference between a good and a bad coding agent running the same model comes down almost entirely to context.
Which one does your problem actually need?
You do not always need the heavier discipline. Here is the test I use.
If your feature handles single-turn requests with no tools and no retrieval, a chatbot answer, a classification, a one-shot rewrite, then prompt engineering may genuinely be all you need. Spend your effort on clear instructions and good examples and stop there. Adding retrieval machinery to a problem that does not have it is its own failure mode.
The moment you add any of three things, you are doing context engineering whether you have a name for it or not: tools the model can call, retrieval from an outside source, or multi-step loops that accumulate state. At that point the dominant question stops being “how do I phrase this?” and becomes “out of everything available, what should the model see right now, in what order, in what format?”
How to level up from prompting to context engineering
The good news is the transition is learnable and you can start today without an agent framework.
Start by auditing. Take any LLM feature you already run and print the exact, final context that hits the model on a real request. Read all of it. Most people have never done this once, and it is humbling. You will find duplicated instructions, stale history, and tool definitions for tools the task cannot even use.
Then practice the strategies in order of effort. First trim and reorder what you already send, since position determines attention and stable prefixes are cache-friendly. Next add a token budget and a compaction step so long sessions do not rot. Then convert pre-loaded data into a tool the model calls on demand, which is the selection move that pays off most. Reach for multi-agent isolation, giving sub-agents their own clean windows, only when a single window genuinely cannot hold the task.
If you want the underlying systems concepts that context engineering borrows from, caching, memory hierarchy, and pipeline design, the system design content on Levelop maps onto it almost one to one. A lot of context engineering is distributed-systems intuition pointed at a context window. Standards like the Model Context Protocol are turning the selection layer into shared infrastructure, which is worth understanding early.
The frontier: context that improves itself
One last reason the center of gravity moved. The research is now treating the context, not the model weights, as the thing you optimize. A Stanford and SambaNova paper on agentic context engineering treats the context as an evolving playbook the agent rewrites as it learns from its own successes and failures, improving agent benchmarks by 10.6 percent with no fine-tuning at all. You cannot do that with a prompt. It is the clearest signal yet that the durable skill of this era is engineering context, not wording requests.
Frequently asked questions
What is the difference between prompt engineering and context engineering?
Prompt engineering optimizes how you phrase a single instruction to a model. Context engineering optimizes everything the model sees at inference time, including the system prompt, retrieved documents, conversation history, tool definitions, and tool outputs, and it does so continuously on every step of a task. Prompt engineering is a writing skill; context engineering is a systems skill.
Is prompt engineering dead in 2026?
No. Prompt engineering was absorbed into context engineering rather than replaced by it. Clear instructions still matter and a poor system prompt still hurts results, but prompting is now one technique among several instead of the whole job. The practical view is that prompt engineering is table stakes and context engineering is the multiplier that decides whether AI output ships.
Should I learn prompt engineering or context engineering first?
Learn prompt engineering basics first, since clear instruction-writing is a prerequisite, then move to context engineering as soon as your application uses tools, retrieval, or multi-step loops. If your use case is purely single-turn with no external data, strong prompting may be all you need.
Why did context engineering replace prompt engineering as the key skill?
Because applications stopped being single-turn. Once you add agents, tools, and retrieval, the hand-written prompt becomes a small fraction of what the model processes, often around 5 percent. The rest is assembled by a system, and managing that system, including the context rot that sets in as the window fills, is what determines success. That work needed its own name.
Do prompt engineering techniques still work inside context engineering?
Yes. Few-shot examples, role framing, chain-of-thought prompting, and output constraints all still work and are used heavily inside context engineering. They are now applied to the components you assemble (the system prompt, tool descriptions, retrieved chunk formatting) rather than to a single standalone message.
Is context engineering the same as RAG?
No. RAG is one technique inside context engineering. Retrieval answers the question of which documents to fetch, while context engineering also covers how many to include, where to place them in the window, when to summarize them away, and how to format them. A strong retriever feeding a bloated, poorly ordered context still produces bad answers.
I've been building Levelop to help engineers learn the systems thinking behind modern AI work. Prompt engineering will get you a decent answer. Context engineering is what turns a model into something that reliably ships.