
What Is Context Engineering? A Developer's Guide
Back with another one in the AI tools series. This one covers the discipline everyone suddenly has a job title for.
For about a year I thought I was good at prompting. I had my templates, my "act as a senior engineer" openers, my carefully worded instructions. Then I started building agents that run for twenty minutes at a time, and all of it stopped mattering. My beautifully crafted prompts were maybe 5 percent of what the model saw. The other 95 percent was tool outputs, file contents, conversation history, and retrieved documents, and I had no system for any of it.
That gap has a name now: context engineering. It is the practice of deciding what information an AI model sees, when it sees it, and how it is structured, across every step of a task. If prompt engineering was about writing the perfect instruction, context engineering is about curating everything else in the window. And in 2026, everything else is where the results come from.
What is context engineering, exactly
Here is the context engineering definition I keep coming back to: context engineering is the set of strategies for selecting, structuring, and maintaining the optimal set of tokens in a model's context window during inference.
The term went mainstream when Andrej Karpathy endorsed it, describing the work as "the delicate art and science of filling the context window with just the right information for the next step." Anthropic's engineering team formalized it in their guide on effective context engineering for AI agents, and it has since become the standard frame for building anything agentic.
The reason this needed a name at all comes down to one constraint: the context window is finite, and attention degrades as it fills. A model with a 200K token window does not treat token 150,000 with the same care as token 500. Researchers call this context rot. Fill the window with everything you have, and the model starts missing instructions it would have nailed in a short conversation.
Most context engineering LLM guides skip the part that matters: what fills the window in a real application.

The prompt you write by hand is a rounding error. The system that assembles the rest is what decides whether the model succeeds.
Context engineering vs prompt engineering
The shortest way I can put the difference: prompt engineering optimizes a single instruction, context engineering optimizes the entire information environment, continuously.
Prompt engineering asks "how do I phrase this request?" Context engineering asks "out of everything available, what should the model see right now, in what order, in what format?" The first is a writing problem. The second is a systems problem, closer to memory management than to copywriting.
Prompting still matters. A sloppy system prompt sabotages everything downstream. But it is now one component inside a larger discipline, the way writing a good function is one component of software architecture. The practical takeaway is this: if your AI feature only handles single-turn requests, prompt engineering may be all you need. The moment you add tools, retrieval, or multi-step loops, you are doing context engineering whether you have a name for it or not.
The five core strategies
Reading through the published guidance from Anthropic, LangChain, and the team behind Manus, the same five strategies show up across agentic systems under different names. Here is how I think about each one.
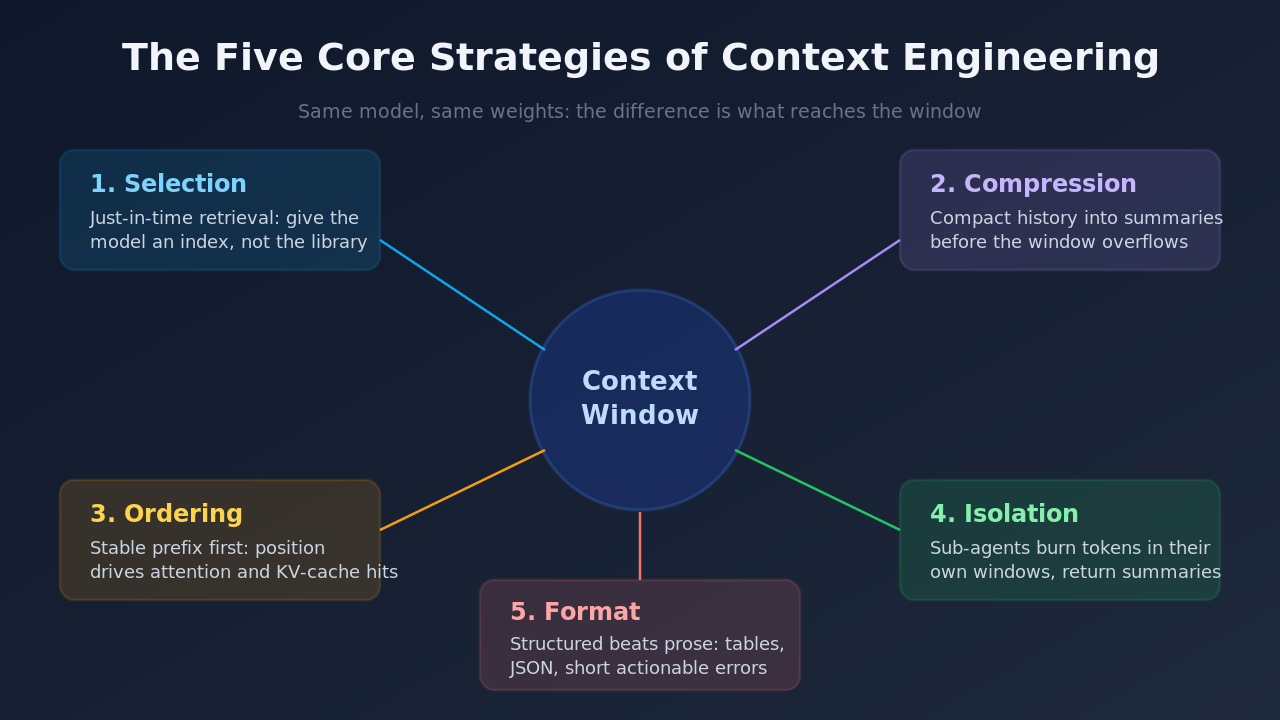
1. Selection: retrieve just enough, just in time
The instinct when you have a knowledge base is to pre-load everything relevant. The better pattern is to give the model lightweight identifiers (file paths, links, queries it can run) and let it pull detail when needed. Anthropic calls this just-in-time retrieval, and it mirrors how a person works: you do not memorize a codebase, you keep it greppable.
In practice this means your agent's first context contains an index, not the content:
# Instead of dumping all docs into context:
context = load_all_documentation() # 80K tokens, mostly irrelevant
# Give the agent a map and a tool:
context = list_doc_titles() # 400 tokens
tools = [read_doc, search_docs] # agent fetches what it needs2. Compression: summarize before you overflow
Long-running agents accumulate history fast. The standard move is compaction: when the window approaches its limit, summarize the conversation so far and start fresh with the summary. Claude Code does this automatically, preserving architectural decisions and unresolved bugs while discarding raw tool outputs that are no longer needed.
The subtle skill is choosing what survives the summary. Compress too aggressively and the agent forgets why it made a decision three steps ago. The Manus team treats this as reversible versus irreversible compression, and keeps anything irreversible (like the original task statement) pinned outside the summarization loop.
3. Ordering: position determines attention
Models pay most attention to the beginning and end of the window. Stable instructions belong at the top. The current task belongs near the bottom. There is a second, less obvious reason ordering matters: KV-cache economics. If the front of your context is byte-for-byte identical across requests, providers can reuse the computation. The Manus team reports cached tokens cost roughly a tenth of uncached ones, which is why they never put timestamps or other volatile data early in the prompt.
4. Isolation: give sub-agents their own windows
The cleanest way to keep a context small is to not put everything in one context. Multi-agent architectures hand focused subtasks to sub-agents with clean windows. A research sub-agent might burn 50K tokens exploring documentation, then return a 1K token summary to the orchestrator. The orchestrator's context stays lean while the heavy reading happens elsewhere. I covered how agentic coding tools use this pattern in my post on how AI coding agents work under the hood.
5. Format: structure beats prose
The same information can cost wildly different token counts depending on format. Every tool call returns output that lands in the window, and outputs returned as compact tables or JSON parse better than paragraphs. Errors should come back as short, actionable messages, not full stack traces. And formats the model saw billions of times in training (markdown, YAML, standard JSON) behave more reliably than clever custom syntaxes.
Where context engineering shows up in real systems
This is not theoretical. Once you know the strategies, you can spot them in every serious AI product.
A RAG pipeline is context engineering: the retrieval step is selection, the reranker is ordering, the chunk format is format optimization. Memory features in ChatGPT and Claude are compression, distilling past conversations into long term memory that gets selectively reinjected. Model Context Protocol servers are selection infrastructure, exposing tools and resources the model pulls on demand instead of pre-loading. Agent harnesses like Claude Code combine all five strategies in one loop.
The pattern even explains why some AI coding agents feel smarter than others running the same underlying model. The model is identical. The context engineering around it is not.
The research frontier pushes this further. A Stanford and SambaNova paper on agentic context engineering (ACE) treats the context itself as an evolving playbook the agent rewrites as it learns, improving agent benchmarks by 10.6 percent without touching model weights. The context, not the model, becomes the thing you train.
A concrete example: the code review bot
Abstract strategies are hard to evaluate, so here is the system that taught me most of this. I built a bot that reviews pull requests. Version one stuffed the entire diff, the full file contents, the style guide, and ten previous reviews into one giant prompt. It worked on small PRs and fell apart on big ones, confidently flagging issues in code that was nowhere near the diff.
Version two applied the five strategies:
def build_review_context(pr):
context = [
STYLE_RULES_SUMMARY, # stable prefix, cache-friendly
pr.title_and_description, # the task
pr.diff_hunks(max_tokens=8000) # selection: diff only
]
# isolation: each changed file reviewed by a sub-call
# with that file's content, results merged after
# compression: prior review comments distilled to one line each
context.append(summarize_prior_reviews(pr.repo))
return contextSame model, same temperature. The false positive rate dropped by more than half, and cost per review fell 70 percent because the cache prefix stopped changing between runs. Nothing about the model improved. Everything about what the model saw did.
Common mistakes I made so you don't have to
The first mistake was treating the context window like a junk drawer. If a tool call returned output, I appended it forever. The fix is aggressive: every token must earn its place, and old tool outputs are usually the first thing to evict.
The second was summarizing the wrong things. My early compaction step preserved chat pleasantries and discarded the list of files the agent had already modified. The agent then re-edited the same file twice. Now I keep a structured scratchpad (files touched, decisions made, open questions) that survives every compaction untouched.
The third was over-engineering selection. I built an elaborate embedding pipeline to decide which docs to inject, when a simple "give the agent grep and let it search" outperformed it. Karpathy's framing cuts both ways: too little context starves the model, but too much machinery between the model and the information adds its own failure modes. Start with the simplest selection mechanism that works.
How to start practicing context engineering
You do not need an agent platform to build this skill. Take any LLM feature you already have and audit it: print the exact final context that hits the model on a real request, and read all of it. Most people have never done this once. You will find duplicated instructions, stale history, and tool definitions for tools the task cannot use.
Then practice the strategies in order of effort. Trim and reorder what you already send (ordering, format). Add a token budget and a compaction step (compression). Convert pre-loaded data into a tool the model calls (selection). Only reach for multi-agent isolation when a single window genuinely cannot hold the task.
If you want a structured path through the underlying systems concepts, the system design track on Levelop covers the caching, memory hierarchy, and pipeline patterns that context engineering borrows from. The mental models transfer almost one to one.
Frequently asked questions
What is context engineering in simple terms?
Context engineering is deciding what information an AI model sees before it answers. That includes instructions, retrieved documents, conversation history, and tool outputs. The goal is to fill the limited context window with only the most useful tokens, structured in the way the model handles best.
Is context engineering replacing prompt engineering?
It absorbed it rather than replaced it. Writing clear instructions still matters, but it is now one of five or so strategies instead of the whole job. Industry guidance from Anthropic and LangChain treats prompting as a subset of context engineering, and most prompt engineer roles have quietly expanded to cover retrieval, memory, and tool design.
Why does context engineering matter for agentic systems specifically?
Agents run in loops, and every loop iteration adds tool outputs and history to the window. Without active curation the context degrades over tens of turns, a failure mode researchers call context rot. A context engineering strategy with compaction and long term memory keeps long-running agents stable where single-turn prompting falls apart.
What is agentic context engineering (ACE)?
ACE is a research framework from Stanford and SambaNova where the agent maintains and evolves its own context as a structured playbook, adding lessons from successes and failures. It improved agent benchmark scores by 10.6 percent without any fine-tuning, showing that context optimization can substitute for weight updates.
What tools help with context engineering?
The current stack includes LangChain and LangGraph for orchestration and state management, MCP servers for standardized tool and resource access, and built-in features of agent harnesses like Claude Code such as auto-compaction, sub-agents, and CLAUDE.md memory files. Observability tools like LangSmith help you inspect what is in the window at each step.
How is context engineering different from RAG?
RAG is one technique inside context engineering. Retrieval answers what documents to fetch. Context engineering also covers what to do with them: how much to include, where to place them, when to summarize them away, and how to format them. A great retriever feeding a bloated, unordered context still produces bad answers.