
AI Agent Evaluation: Metrics, Traces, and Tool-Calling Tests
Your agent answered the question, so the demo looked great. Then it shipped, and a week later you learned it had been calling the wrong API, retrying three times, and burning tokens on a detour no user ever asked for. The final answer was fine. Everything that happened on the way to it was not. This is the problem AI agent evaluation exists to solve. Grading the last message tells you almost nothing about whether the agent did the right thing, and an agent that reaches a correct answer through a broken process will eventually reach a wrong one.
Evaluating an agent is a harder problem than evaluating a single model response, because an agent is a loop, not a function. It plans, calls tools, reads results, and decides what to do next, often across many steps. A good evaluation has to look at that whole path. This guide covers the metrics that matter, how to score the trajectory rather than just the output, how to test tool calling specifically, and the frameworks that wrap all of it into something you can run in continuous integration. It builds on our broader guide to what LLM evaluation is, so if evals are new to you, start there and come back.
What is AI agent evaluation?
AI agent evaluation is the practice of measuring whether an autonomous agent completes its task correctly, efficiently, and safely across the full sequence of steps it takes, not just at the final answer. An agent is a language model wrapped in a loop that can reason, call external tools, observe the results, and act again until it decides the job is done. Because of that loop, there are many more places for it to go wrong than there are in a single prompt and response.
Think of the difference this way. Evaluating a plain model output is like grading an exam answer. Evaluating an agent is like grading the student's entire working, including which textbooks they opened, which formulas they applied, and whether they wandered down a dead end before arriving at the result. Two agents can return the same correct answer while one took two clean steps and the other took eleven, called a paid API four times, and got lucky. Only one of those is production ready.
This is why agent evaluation borrows the techniques of single-output evaluation, including the LLM-as-a-judge pattern, but adds a whole second dimension: the process. You end up measuring two things at once. Did the agent get the right outcome, and did it get there the right way.
Why evaluating agents is harder than evaluating a single response
Three properties of agents make them resistant to the evaluation methods that work fine for a single model call.
The first is compounding error. If each step in a five-step task is ninety percent reliable, the end-to-end success rate is not ninety percent. It is roughly fifty-nine percent, because the failures multiply. Long-horizon tasks magnify small per-step weaknesses into large end-to-end ones, which means a metric that only checks the final answer hides where the reliability is actually leaking.
The second is non-determinism. The same agent given the same input can take different paths on different runs, depending on sampling, tool latency, and the order in which results come back. A single passing run proves very little. You need to run the same scenario repeatedly and look at the distribution of outcomes, not a single trace.
The third is the lack of a single ground truth. For a math problem there is one right answer, but for a request like book me a reasonable flight and add it to my calendar there are many acceptable trajectories and many acceptable outcomes. Evaluation has to judge whether the path was sensible, not whether it matched one gold sequence exactly. That pushes agent evaluation toward rubric-based and judge-based scoring rather than simple string matching.
The core AI agent evaluation metrics
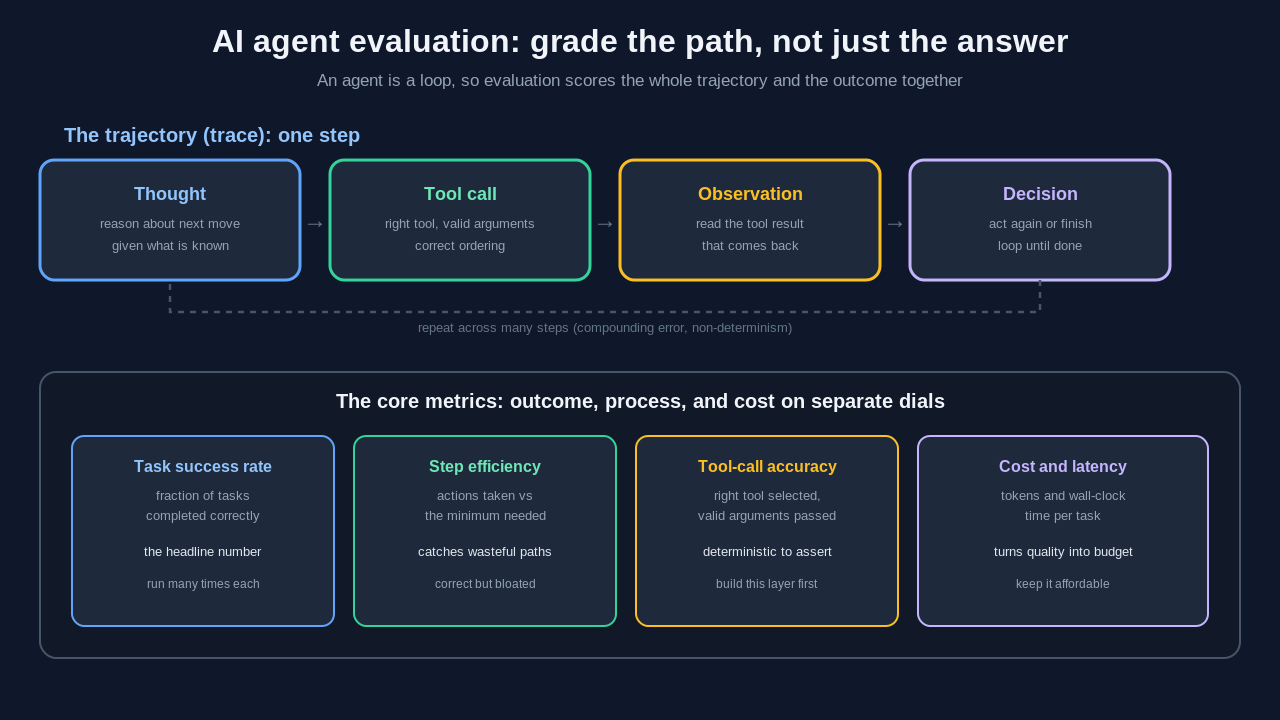
A useful agent evaluation tracks a small set of metrics that together cover outcome, process, and cost. These are the AI agent evaluation metrics worth instrumenting from day one.
Task success rate is the headline number: across a suite of representative tasks, what fraction did the agent complete correctly. This is the metric your stakeholders care about, and it is the one you defend a release on. Define correct precisely for each task, because a fuzzy success definition produces a meaningless rate. Measure it over many runs per task to account for non-determinism.
Task completion is a related but softer signal. It asks whether the agent finished at all, regardless of correctness, which separates agents that fail loudly from agents that silently give up or loop forever. An agent can have decent success on the tasks it finishes while abandoning a quarter of them, and you only see that gap if you track completion separately.
Step efficiency measures how many actions the agent took relative to the minimum needed. An agent that solves a task in twelve tool calls when three would do is slow, expensive, and fragile, even when it succeeds. Tracking the step count exposes the wasteful-but-correct trajectories that a success-only view rewards by accident.
Tool-call accuracy measures whether the agent selected the right tool and passed it valid arguments. Wrong tool selection and malformed arguments are among the most common agent failure modes, and they are invisible if you only read the final message. We treat this as important enough to deserve its own section below.
Cost and latency close the loop on the practical question of whether the agent is affordable to run. Token spend per task and wall-clock time per task turn quality into a budget. An agent that is correct but costs a dollar per query may not survive contact with real traffic.
Trajectory evaluation: scoring the path, not just the answer
The single most important idea in agent evaluation is the trajectory, also called the trace. The trajectory is the ordered record of everything the agent did: each reasoning step, each tool call with its arguments, each observation it got back, and each decision about what to do next. Agent trajectory evaluation scores that record, which is where the real signal about agent quality lives.
There are two broad ways to grade a trajectory. The first is to compare it against a reference path. You define an ideal sequence of steps for a task and measure how closely the agent's actual sequence matches, using an exact match for strict tasks or a more forgiving in-order or any-order match when several valid routes exist. This works well for tasks with a known-good procedure and poorly for open-ended ones.
The second is to use an LLM judge to grade the trajectory holistically. You hand the full trace to a capable model along with a rubric and ask whether the steps were logical, whether each tool call was justified by what the agent knew at that point, and whether the agent recovered sensibly when a step failed. This is the only practical approach for tasks where many different paths are acceptable, and it inherits both the power and the biases of the judge pattern.
A complete trajectory record for a single step usually looks something like this, captured as structured data your evaluator can parse.
# One step in an agent trajectory, captured for evaluation
step = {
"step": 3,
"thought": "I have the user's city. Now I need the current weather.",
"tool_call": {
"name": "get_weather",
"arguments": {"city": "Austin", "units": "imperial"},
},
"observation": {"temp_f": 96, "conditions": "clear"},
"decision": "Temperature retrieved. Proceed to format the answer.",
}When you evaluate that step, you are not asking whether the weather was 96 degrees. You are asking whether calling the weather tool was the right move given what the agent knew, whether the arguments were well formed, and whether the next decision followed from the observation. That is process evaluation, and it catches the failures that outcome evaluation sleeps through. Maintaining this kind of structured record in production is exactly what LLM observability tooling is built to do.
Tool-calling evaluation: the failure mode that hides
Tool calling is where agents most often break in ways that final-answer scoring cannot see. An agent can pick a plausible-sounding tool that is wrong for the task, call the right tool with a misspelled or missing argument, hallucinate a tool that does not exist, or call tools in an order that corrupts state. Tool calling evaluation isolates each of these.
There are three layers worth testing. The first is tool selection: given a task and a set of available tools, did the agent choose the correct one. You can test this directly by constructing scenarios with a known correct tool and checking the agent's choice, which gives you a clean accuracy number per tool. The second is argument construction: when the agent calls a tool, are the arguments syntactically valid and semantically correct, matching the tool's schema and the user's actual intent. The third is call sequencing: when a task needs several tools in order, did the agent respect dependencies, for example fetching an ID before using it.
Here is a compact tool-selection test that checks both the chosen tool and its arguments against an expected call. This is the kind of assertion you run in continuous integration on every prompt change.
def test_tool_selection(agent):
task = "What's the weather in Austin right now?"
trace = agent.run(task)
first_call = trace.tool_calls[0]
# Did the agent pick the right tool?
assert first_call.name == "get_weather", \
f"Expected get_weather, got {first_call.name}"
# Did it pass valid, correct arguments?
assert first_call.arguments.get("city") == "Austin", \
"City argument missing or wrong"Tool-calling tests are cheap to write and catch a disproportionate share of real agent bugs, because tool errors are deterministic enough to assert on directly. Unlike final-answer quality, a wrong tool name is unambiguously wrong, so you do not need a judge to grade it. Build this layer first.
How to build an agent evaluation suite
A practical agent evaluation suite comes together in five moves, and you can stand up a first version in an afternoon.
Start by building a dataset of representative tasks. Pull real examples from logs where possible, cover the easy cases and the known-hard ones, and for each task write down precisely what a correct outcome looks like. A few dozen well-chosen tasks beat a thousand random ones. Next, decide your success criteria per task, because correct means different things for a lookup versus a multi-step booking, and a vague definition makes the whole rate meaningless.
Then instrument your agent to emit full trajectories. You cannot evaluate a path you did not record, so capture every reasoning step, tool call, argument, and observation as structured data. With traces flowing, layer in the metrics: compute task success rate and completion from outcomes, step efficiency and tool-call accuracy from the trajectory, and cost and latency from the run metadata. Finally, run the suite repeatedly rather than once, because non-determinism means a single pass tells you little. Run each task several times and read the distribution, then wire the whole thing into continuous integration so a prompt change that drops success rate fails the build the same way a broken unit test would.
The discipline here mirrors how mature teams already treat prompts and context as engineered artifacts. If that framing is new, our guide on context engineering covers the surrounding practice, and the whole approach fits the philosophy we describe across the Levelop blog.
Tools for AI agent evaluation in 2026
You do not have to build the harness from scratch. Several frameworks now handle agent-specific evaluation, including trajectory and tool-call scoring, out of the box.
DeepEval extends its pytest-style test cases to agents, with metrics for task completion, tool correctness, and trajectory quality that you run in continuous integration and get a pass or fail on. LangSmith, from the LangChain team, focuses on tracing and offers trajectory evaluation that compares an agent's actual path against a reference sequence, with deep visibility into each step. Langfuse is an observability platform first, combining traces, latency, cost, and evaluation in one dashboard, which makes it a natural fit for the run-and-inspect loop agent debugging demands. Research benchmarks such as AgentBench and tau-bench provide standardized multi-turn, tool-using tasks if you want to measure your agent against a public bar rather than only your own dataset.
Most teams end up combining two layers: an observability tool to capture and inspect trajectories, and an evaluation framework to assert on them in continuous integration. The two are complementary, and the better observability platforms let you pull failing real-world traces straight into your test suite, so production incidents become regression tests automatically.
Conclusion
Evaluating an AI agent is fundamentally about refusing to be impressed by a correct final answer. The answer is the easy part to check and the least informative. What separates an agent you can ship from one that will embarrass you in production is the path it took: whether it picked the right tools, passed them valid arguments, recovered from failure, and reached the goal without wandering or burning money. Track task success rate for the headline, but track step efficiency, tool-call accuracy, and trajectory quality for the truth.
Start small. Build a few dozen representative tasks, instrument your agent to emit full traces, write direct assertions on tool selection, and run the suite in continuous integration. That foundation will catch more real bugs than any amount of staring at final outputs. For the broader picture of how this fits into evaluating AI systems, see our pillar guide on LLM evaluation, and explore more engineering deep dives on the Levelop blog.
Frequently asked questions
What is the difference between AI agent evaluation and LLM evaluation?
LLM evaluation grades a single model response: was this answer accurate, relevant, and safe. AI agent evaluation grades a multi-step process: did the agent plan well, call the right tools with valid arguments, recover from errors, and reach the goal efficiently across the whole loop. Agent evaluation includes output quality but adds the entire dimension of process and trajectory, which single-response evaluation ignores.
What is the most important AI agent evaluation metric?
Task success rate is the headline metric, since it answers whether the agent completes representative tasks correctly. But it is dangerous in isolation, because an agent can succeed through wasteful or wrong intermediate steps. Pair it with step efficiency and tool-call accuracy so a clean outcome cannot hide a broken process.
What is trajectory evaluation for AI agents?
Trajectory evaluation, also called trace evaluation, scores the full ordered record of an agent's run: every reasoning step, tool call, observation, and decision. You can grade it by comparing against a reference path for strict tasks, or by using an LLM judge with a rubric for open-ended tasks where many paths are acceptable. It catches process failures that final-answer scoring misses.
How do you test an agent's tool calling?
Test three layers. Tool selection checks whether the agent chose the correct tool for the task. Argument construction checks whether the arguments are valid and match the tool's schema and the user's intent. Call sequencing checks whether multi-tool tasks respect dependencies and ordering. Because tool errors are deterministic, you can assert on them directly in continuous integration without needing an LLM judge.
How many times should you run each evaluation task?
More than once, always. Agents are non-deterministic, so a single passing run proves little. Run each task several times, often five to ten, and read the distribution of outcomes rather than a single result. Report success rate as a fraction across runs, and watch the variance, because a wide spread is itself a reliability signal.
Can you use an LLM to evaluate an AI agent?
Yes, and it is often the only practical option for open-ended tasks. An LLM judge can grade a trajectory holistically, deciding whether each step was justified and whether the agent recovered sensibly from failures. The same cautions from the LLM-as-a-judge pattern apply: judges carry biases, so calibrate them against human ratings and rotate judge models to avoid self-preference.
Where to go next
AI agent evaluation is one pillar of a larger evaluation discipline. To see how it connects to scoring single outputs and watching systems in production, read our pillar guide to LLM evaluation, then explore LLM-as-a-judge for grading output with another model and LLM observability for monitoring agents in production. For more developer guides on building with AI, visit the Levelop blog or the Levelop home page.