
LLM-as-a-Judge: How to Evaluate AI Output With Another Model
You shipped a feature that uses a language model. Now your product manager asks the obvious question: is the output any good? You cannot read every response by hand, and a regex never captures whether an answer was helpful, accurate, or on-brand. This is the gap that LLM-as-a-judge fills. You use one model to grade the output of another, at a scale no human review team could match.
The technique has moved from research curiosity to default practice. Most teams running AI in production now lean on an LLM judge for the quality signals that traditional metrics miss. This guide explains how the pattern works, the prompts and scoring methods that make it reliable, the biases that quietly wreck it, and the tools that wrap the whole thing in a test suite. It is a practical companion to our broader guide on what LLM evaluation is, so if you are new to evals, start there and come back.
What is LLM-as-a-judge?
LLM-as-a-judge is the practice of using a language model to score, classify, or compare the outputs of another AI system. Instead of asking a human reviewer to decide whether a chatbot reply was helpful, you send the reply to a second model along with a rubric and ask it to return a verdict. The judge can output a number, a label, a pass or fail, or a preference between two candidates.
The reason this matters is that the hardest qualities to measure are also the most important. Exact-match scoring tells you whether a model produced a specific string. It says nothing about whether a summary was faithful, whether a support answer was polite, or whether a generated email stayed on message. Those are judgment calls, and until recently only people could make them. An LLM grader gives you a way to automate that judgment and run it on thousands of examples in minutes.
Using an LLM to evaluate another LLM sounds circular, and the skepticism is healthy. The justification is empirical, not philosophical: when researchers compared judge verdicts against human ratings, the strongest models agreed with people about as often as people agreed with each other.
Why use an LLM to evaluate another LLM?
The case for the LLM judge rests on three properties: it scales, it is cheap relative to human review, and it correlates with human preference well enough to be useful.
Studies that benchmarked GPT-4 against human annotators found roughly 80 percent agreement with human preference scores, which is close to the rate at which human annotators agree with themselves. Later work pushed agreement as high as 85 percent for both pairwise and single-output scoring, edging past the roughly 81 percent agreement humans reach with one another. The headline is not that the judge is perfect. The headline is that a well-built judge is about as consistent as your human reviewers, and it never gets tired, never goes on vacation, and returns a verdict in seconds.
That changes what you can do operationally. You can grade every response in a nightly batch instead of sampling one in a hundred. You can gate a pull request on quality, the same way you gate it on passing unit tests. You can catch a regression the moment a prompt change degrades output, rather than waiting for a user complaint. For teams that already treat prompts and context as engineering artifacts, this is the missing feedback loop. If that framing is new to you, our guide on context engineering covers the surrounding discipline.
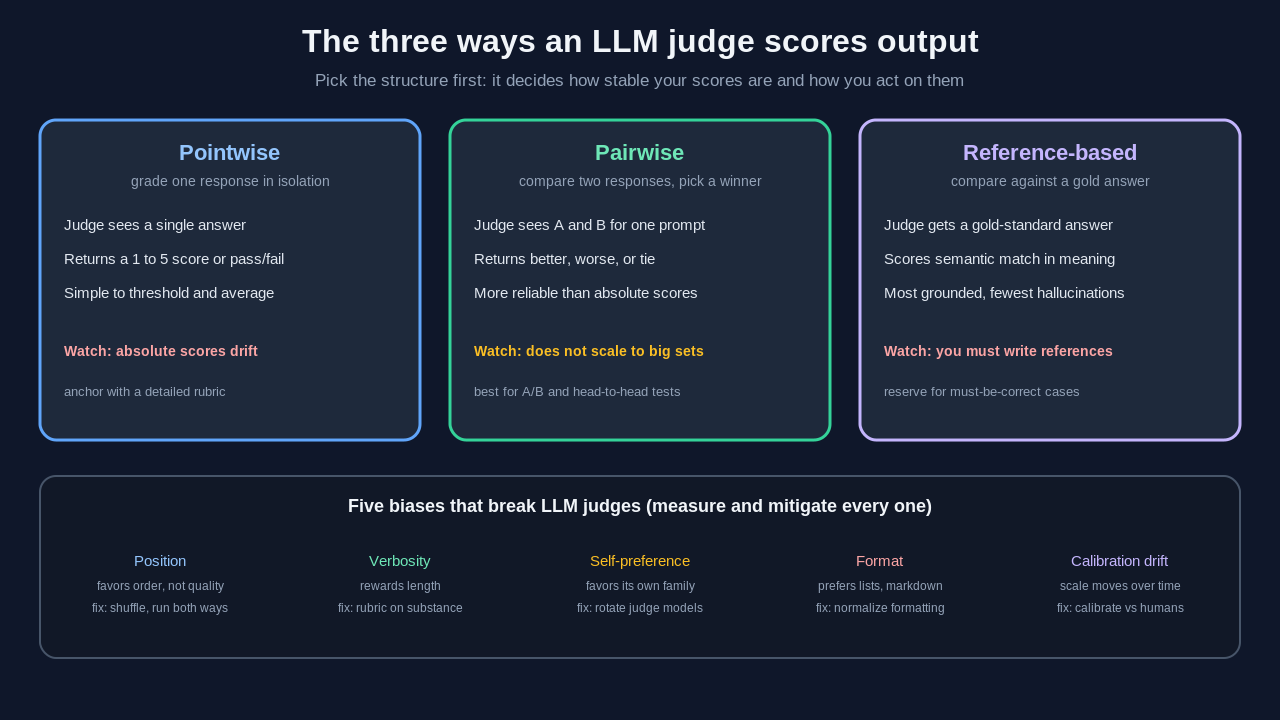
The three ways an LLM judge scores output
Almost every LLM-as-a-judge setup uses one of three scoring structures. Picking the right one is the single biggest decision you will make, because it determines how stable your scores are and how you act on them.
Pointwise scoring
In pointwise scoring, the judge looks at one response in isolation and assigns it a score, usually on a Likert scale such as one to five, or a binary pass or fail. This is the simplest pattern and the easiest to act on, because every output gets an absolute grade you can threshold or average.
The catch is stability. Absolute scores assume the model has a consistent internal sense of what a four versus a five means, and that sense drifts. The same answer can earn a four today and a three tomorrow. Pointwise scoring works best when you give the judge a detailed rubric and concrete examples for each score level, which anchors the scale and reduces wobble.
Pairwise evaluation
In pairwise evaluation, the judge sees two responses to the same prompt and decides which one is better, with the option to call a tie. This maps naturally onto the question teams actually ask: is the new model or prompt better than the old one? Pairwise comparison tends to be more reliable than pointwise scoring because relative judgments are easier and more consistent than absolute ones.
The cost is scale. Comparing every output against every other output explodes combinatorially, so pairwise evaluation is best for head-to-head tests, A/B comparisons of prompt versions, and ranking a small set of candidates rather than grading a large dataset.
Reference-based scoring
In reference-based scoring, you give the judge a gold-standard answer alongside the question and the response, and ask how well the response matches the reference in meaning. This is the most grounded of the three because the judge has something concrete to compare against, which sharply reduces hallucinated verdicts. The limitation is obvious: you need reference answers, and writing them is the same labor-intensive work you were trying to avoid. Reserve this pattern for the cases where correctness is non-negotiable and you can afford to build a labeled set.
How to write an LLM judge prompt
The prompt is where most LLM judges live or die. A vague instruction like "rate this answer from one to ten" produces noise. A good judge prompt does four things: it states the role, it defines each score level with criteria, it asks for reasoning before the verdict, and it pins the output to a parseable format.
Here is a pointwise judge prompt that follows the structure. Asking for reasoning first is not decoration; chain-of-thought prompting is the core idea behind G-Eval, a framework that uses step-by-step reasoning to make LLM judges measurably more stable and accurate.
JUDGE_PROMPT = """You are an expert evaluator grading a customer-support reply.
Question:
{question}
Reply to evaluate:
{answer}
Score the reply from 1 to 5 on helpfulness using this rubric:
5 - Fully resolves the question, accurate, and clearly worded.
4 - Resolves the question with a minor omission or awkward phrasing.
3 - Partially helpful; misses an important part of the question.
2 - Largely unhelpful or contains a factual error.
1 - Irrelevant, wrong, or harmful.
First, reason step by step about how the reply meets or fails each
rubric level. Then output your verdict as strict JSON:
{{"reasoning": "<your analysis>", "score": <integer 1-5>}}
"""A few rules pay off every time. Keep the rubric specific and tied to observable features of the answer, not vague adjectives. Force structured output so you can parse it programmatically. Use a capable model as the grader, since the judge needs to be at least as strong as the model it grades. And version the prompt: treat your judge prompt as code, because changing it changes every score it ever produces.
The biases that break LLM judges
The uncomfortable truth is that LLM judges carry systematic biases, and in adversarial tests even frontier models have exceeded a 50 percent error rate on bias probes. Consistency can break on changes as trivial as reformatting or paraphrasing. If you deploy a judge without accounting for these, your scores will look authoritative while being quietly wrong. There are five named biases worth knowing.
Position bias is the tendency to favor a response based on where it appears. In pairwise evaluation, judges often prefer whichever answer comes first, or whichever comes last, regardless of quality. Verbosity bias is the tendency to reward longer answers, treating length as a proxy for quality even when the extra words add nothing. Self-preference bias is the tendency of a judge to favor text generated by itself or its own model family, which is why grading a model with a judge from the same family is risky. Format bias is sensitivity to surface structure, such as preferring bulleted lists or markdown over equivalent prose. Calibration drift is the slow movement of the score scale over time and across model versions, so that today's four is not last month's four.
How to make an LLM judge reliable
The good news is that every one of these biases has a known countermeasure, and the fixes are mechanical rather than mysterious. Reliability comes from treating the judge as a system you maintain, not a prompt you write once.
Start with position bias, which is the cheapest to fix. Shuffle the order of candidates on every pairwise call, and for high-stakes comparisons run the judgment both ways and keep the result only if it agrees with itself. To blunt self-preference bias, rotate judges across model families so no single model grades its own output, and never use the same model as both generator and sole judge. Use chain-of-thought prompting, the G-Eval approach, to stabilize verdicts and surface the judge's reasoning. Pin the judge contract, meaning the exact prompt, model version, and parsing logic, and treat any change to it as an eval-suite migration rather than a casual config tweak.
Most important, calibrate against humans on a schedule. Periodically have people grade a sample of the same outputs the judge grades, and measure how often the judge agrees with them. If agreement drops, your judge has drifted and needs attention. A judge swap should be treated with the same care as a model upgrade, because it can silently shift every number on your dashboard. This kind of ongoing measurement is exactly what production LLM observability tooling is built to support.
Tools for LLM-as-a-judge in 2026
You do not have to build the harness yourself. Several mature open-source frameworks wrap LLM-as-a-judge in a developer-friendly interface, and most report agreement with human raters in the 85 to 92 percent range when configured well.
DeepEval is the closest thing to pytest for LLMs. You write evals as test cases, run them in continuous integration, and get a pass or fail on metrics like answer relevance, hallucination, and bias. It has the broadest metric library and extends past retrieval-augmented generation into agents and chatbots. Ragas focuses on retrieval-augmented generation with a small set of targeted metrics and first-class adapters for LangChain and LlamaIndex, and many of its metrics need no ground-truth labels. Promptfoo shines at prompt regression testing, letting you track how output quality shifts as you iterate and catch regressions before they ship. Langfuse is an observability platform first, combining traces, latency, cost, and evaluation in one dashboard, and it integrates with the others so you can pull test cases from real traces.
Here is what an LLM judge looks like as a unit test with DeepEval. The metric runs another model behind the scenes to produce the score.
from deepeval import assert_test
from deepeval.metrics import GEval
from deepeval.test_case import LLMTestCase, LLMTestCaseParams
helpfulness = GEval(
name="Helpfulness",
criteria="Does the reply fully and accurately resolve the user's question?",
evaluation_params=[
LLMTestCaseParams.INPUT,
LLMTestCaseParams.ACTUAL_OUTPUT,
],
threshold=0.7,
)
def test_support_reply():
case = LLMTestCase(
input="How do I reset my password?",
actual_output="Go to Settings, click Security, then Reset password.",
)
assert_test(case, [helpfulness])For a deeper comparison of where each tool fits across the evaluation lifecycle, the pillar guide to LLM evaluation and our guide to AI agent evaluation go further on metrics and traces.
When not to use an LLM judge
The LLM judge is a tool, not a religion. Skip it when a cheaper, deterministic check will do. If you can verify correctness with an exact match, a JSON schema, a unit test, or a regular expression, use that, because deterministic checks are faster, free, and never biased. Reserve the LLM judge for the qualities that genuinely require judgment, such as helpfulness, tone, faithfulness, and coherence. And for anything truly high-stakes, keep a human in the loop. The judge narrows the field of what humans need to review; it does not eliminate the need for human oversight where the cost of a wrong call is high.
Frequently asked questions
What is LLM-as-a-judge?
LLM-as-a-judge is the practice of using one language model to evaluate the output of another. You give the judge model the output, a rubric, and an instruction to score, classify, or compare, and it returns a verdict such as a number, a label, or a preference. It automates the kind of quality assessment that previously required a human reviewer.
How accurate is an LLM judge compared to humans?
In benchmark studies, strong models such as GPT-4 agreed with human preference ratings roughly 80 to 85 percent of the time, which is comparable to how often human annotators agree with each other (around 81 percent). A well-configured judge is about as consistent as a human reviewer, but it is not infallible and should be calibrated against humans regularly.
What is the difference between pointwise and pairwise evaluation?
Pointwise scoring grades a single response in isolation, usually on a numeric scale, which is simple to act on but less stable. Pairwise evaluation shows the judge two responses and asks which is better, which is more reliable because relative judgments are easier than absolute ones, but it does not scale to large datasets. Use pointwise for grading at scale and pairwise for head-to-head comparisons.
What biases affect LLM judges?
The five common biases are position bias (favoring an answer by its order), verbosity bias (rewarding longer answers), self-preference bias (favoring its own model family's output), format bias (preferring certain surface structures), and calibration drift (the score scale moving over time). Even frontier models fail bias probes more than half the time in adversarial tests, so biases must be measured and mitigated directly.
Which tools support LLM-as-a-judge?
Popular open-source options include DeepEval for test-suite-style evals in continuous integration, Ragas for retrieval-augmented generation metrics, Promptfoo for prompt regression testing, and Langfuse for combining evaluation with production observability. Most report 85 to 92 percent agreement with human raters when set up carefully.
Where to go next
LLM-as-a-judge is the engine behind most modern AI evaluation, but it is one piece of a larger discipline. To see how it fits into offline and online evaluation, metrics, and monitoring, read our pillar guide to LLM evaluation, then explore AI agent evaluation for grading tool-calling agents and LLM observability for watching all of it in production. For more developer guides on building with AI, visit the Levelop blog or the Levelop home page.