
What Is LLM Evaluation? A Developer's Guide to AI Evals in 2026
If you shipped a feature backed by a large language model this year, you already know the uncomfortable truth: the demo worked, and then production did something nobody predicted. A summarizer invented a number. A support agent called the wrong tool. A coding assistant confidently rewrote a file it should have left alone. None of these showed up in a code review, because none of them are bugs in the traditional sense. They are failures of behavior, and you catch behavior with LLM evaluation.
LLM evaluation is the practice of measuring whether large language models (LLMs) and the AI systems built on them actually do what you need, repeatedly and at scale. It turns vague impressions into evaluation results you can compare release over release. In 2026 it has stopped being a research nicety and become the core engineering discipline of the AI era. Practitioner reports now put evaluation at 60 to 80 percent of the work on successful AI product teams, which is a polite way of saying that the writing of the prompt is the easy part and proving it works is the job.
This guide walks through what LLM evaluation is, why deterministic testing fails for non-deterministic systems, the metric families that matter, how teams use one model to grade another, and how to build an evaluation loop you can actually trust. It is the pillar of a four-part series, so when you want to go deeper on a specific technique you can follow the links into the companion posts.
Why traditional testing breaks on language models
A normal unit test asserts that a function returns an exact value. Given the same input, it always produces the same output, so the assertion is binary and reproducible. Language models break both halves of that contract. The same prompt can return different text on two calls, and "correct" is rarely a single string. There are many good ways to summarize a document and many acceptable ways to answer a question, so an exact-match assertion has nothing to compare against.
Agents make this harder. An agent operates across a multi-step workflow, and a single early mistake can cascade. A small misunderstanding, a bad tool call, or a broken assumption compounds across hundreds of reasoning loops, so the failure you observe at the end may have started ten steps earlier. You cannot debug that with a stack trace. You need to score the whole trajectory, not just the final answer.
This is why evaluation is its own layer rather than an extension of your existing test suite. It accepts that outputs are probabilistic, defines "good" as a measurable property rather than an exact match, and gives you a number you can track over time. Once you have that number, regressions become visible, prompt changes become measurable, and "it feels better" turns into "faithfulness went up four points."
Offline and online evaluation: the two halves of the loop
Mature teams run evaluation in two places, and the distinction matters because each catches a different class of failure.
Offline evaluation runs against a curated dataset before you ship, usually in continuous integration on every pull request or on a schedule. Because the dataset is fixed, the run is reproducible, which makes it the right place to compare a new prompt against the old one or to gate a deploy. Think of it as the regression suite for behavior. You assemble a set of representative inputs with expected properties, define clear evaluation criteria for each, run your system against them, and read the aggregate scores.
Online evaluation runs against real traffic after you ship, and it catches the failures that only appear in the wild. Real users phrase things in ways your dataset never anticipated, and distribution drift means today's traffic does not look like last month's. Online scoring sits on top of live requests and user feedback, and it feeds drift detection. A four-point faithfulness drop over a week is a regression that latency dashboards will never show you, because nothing is slow or erroring, the answers are just quietly getting worse.
The two reinforce each other. Online evaluation surfaces a new failure mode, you capture those examples, you add them to the offline dataset, and the next regression of that kind gets caught before it ships. That feedback loop, not any single tool, is what separates teams that ship reliable AI from teams that keep firefighting.
The metric families that actually matter
There is a long tail of possible metrics, but five families cover most production workloads. Pick the ones that map to how your system can fail rather than measuring everything.
Task completion measures whether the model accomplished the user's actual goal. For an agent this is the headline number, often expressed as task success rate. Faithfulness, sometimes called groundedness, measures whether the output stays anchored to the provided context instead of inventing facts. This is the hallucination metric, and it matters most for retrieval-augmented systems where a fluent, plausible answer can still contradict the source documents. Tool-use correctness measures whether an agent called the right tool, with the right arguments, in a reasonable number of steps. Safety covers toxicity, leaked personal data, jailbreak susceptibility, and brand-tone violations. Latency and cost measure operational health, because an answer that is correct but takes thirty seconds or burns a dollar in tokens is still a product problem.
Notice that most of these are not exact-match metrics. You cannot regex your way to a faithfulness score. That is exactly why a second model has become the dominant way to grade the first.
# evals/metrics.py
# A minimal offline eval: score each case, then aggregate.
from statistics import mean
def run_eval(system, dataset, scorers):
rows = []
for case in dataset:
output = system(case["input"])
scores = {name: fn(case, output) for name, fn in scorers.items()}
rows.append(scores)
# Aggregate: a single regressing metric should fail the run.
return {name: round(mean(r[name] for r in rows), 3) for name in scorers}
# scorers map a (case, output) pair to a 0..1 score.
# task_success and faithfulness below are typically LLM-as-a-judge calls.
report = run_eval(my_agent, golden_set, {
"task_success": score_task_success,
"faithfulness": score_faithfulness,
"tool_correctness": score_tool_calls,
})
print(report) # {'task_success': 0.91, 'faithfulness': 0.86, 'tool_correctness': 0.94}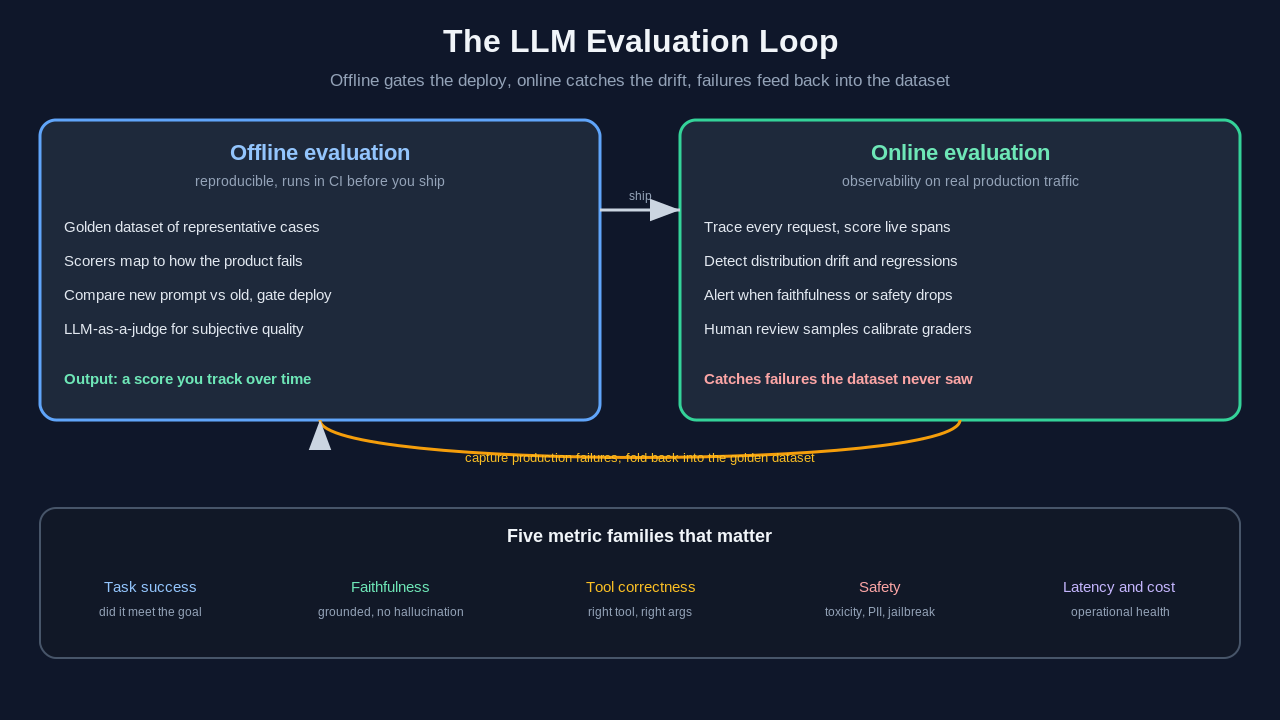
LLM-as-a-judge: using one model to grade another
When the property you care about is subjective, the scalable answer in 2026 is to ask a capable model to score the output against a rubric. This is LLM-as-a-judge, and the appeal is obvious. It offers something like 500x to 5000x cost savings over human review while reaching roughly 80 percent agreement with human preferences on many tasks. That is good enough to run on every pull request and on live traffic, which human graders never could.
The catch is that judges have biases, and the research community spent the last two years cataloguing them. Position bias is the tendency to favor whichever answer appears first in a pairwise comparison, and on close calls it can swing the win rate by ten to fifteen points. Verbosity bias rewards longer answers regardless of quality. Self-preference bias means a model tends to rate its own family of outputs more highly. Format changes and paraphrasing can flip a verdict that should not change at all. A widely cited study of position bias and related work found that no judge tested was uniformly reliable across benchmarks, so treating a judge's score as ground truth is a mistake.
The fix is engineering discipline, not abandoning the technique. Write an explicit rubric instead of asking "is this good." Shuffle or rotate the order of candidates to cancel position bias. Calibrate the judge against a small human-labeled set so you know its error rate. Keep the judge model and its prompt versioned, because a silent judge change invalidates every historical score. Treat your evaluator as a system you also have to evaluate.
# evals/judge.py
JUDGE_RUBRIC = """You are grading a support answer against a rubric.
Score 1 to 5 on each axis and return JSON.
- groundedness: every claim is supported by the CONTEXT
- relevance: the answer addresses the QUESTION
- completeness: no required step is missing
Penalize confident claims not present in CONTEXT.
Return: {"groundedness": n, "relevance": n, "completeness": n, "reason": "..."}"""
def judge(question, context, answer, model):
msg = f"QUESTION:\n{question}\n\nCONTEXT:\n{context}\n\nANSWER:\n{answer}"
# Run twice with the answer order swapped to cancel position bias,
# then average the two passes before trusting the score.
return model.json(system=JUDGE_RUBRIC, user=msg)The companion post on LLM-as-a-judge goes through rubric design and bias mitigation in detail.
Evaluating agents is a different sport
Scoring a single prompt-and-response pair is the easy case. Agents that plan, call tools, and loop, often across multi turn conversations, need trajectory evaluation, which looks at the sequence of decisions rather than only the final output. Two numbers matter most here. System efficiency metrics track token usage, completion time, and the number of tool calls, because an agent that reaches the right answer after fourteen wasteful steps is fragile. Agent quality metrics track task success, trajectory soundness, and tool correctness, asking whether each step was a reasonable thing to do given what the agent knew at that point.
This is where evaluation and the Model Context Protocol intersect. When an agent's tools are exposed over a standard interface, your evaluator can inspect exactly which tool was called with which arguments, which makes tool-correctness scoring far more precise. If you are building agentic systems, it is worth reading how MCP works and the security risks MCP introduces, because the same trace data that powers evaluation also powers your audit trail. The dedicated companion post on AI agent evaluation covers metrics, traces, and tool-calling tests end to end.
Offline scores are not enough: observability closes the loop
Pre-merge scores tell you the system was good against your dataset on the day you shipped. They say nothing about Tuesday afternoon when a model provider quietly updated a checkpoint or a new customer started asking questions your dataset never covered. That is the job of observability: tracing every request, attaching scores to live spans, and alerting when a metric drifts.
Anthropic's 2026 evaluation guidance is explicit on this point, describing post-launch monitoring as a requirement rather than an option, with systematic human review calibrated against automated graders to catch distribution drift and real-world failures. In practice that means your production traces carry the same automated evaluations as your offline suite, so a faithfulness regression triggers an alert the same way a latency spike would. Human evaluation still has a role here, sampling traces to keep the automated graders honest, but human judgment does not scale to every request, which is why the two work together. The companion post on LLM observability covers tracing and production monitoring in depth.
The tooling landscape in 2026
You do not have to build all of this yourself. The ecosystem split into two camps that work well together. For offline evaluation, open-source frameworks lead. DeepEval offers a pytest-style experience with a library of metrics including G-Eval, RAG, agent, and conversational scorers. Ragas focuses on retrieval-augmented generation. Promptfoo is CLI-first with YAML configuration, which makes it easy to drop into continuous integration. For online evaluation and tracing, observability platforms such as Langfuse, LangSmith, Arize, and Braintrust capture production traces and let you attach scores to live traffic.
The right starting point is smaller than the catalog suggests. Pick one offline framework, wire it into CI against a golden dataset of fifty cases, and pick one tracing tool for production. Expand only when a real failure tells you what you are missing.
How to start an evaluation practice this week
Begin by collecting failures. Every time someone on the team notices the model doing something wrong, capture the input and a note about what good would have looked like. Within a week you have the seed of a dataset that reflects your real failure modes rather than imagined ones. Turn those into a golden set of representative cases with expected properties, write two or three scorers that map to how your product actually fails, and run them in CI so every prompt change produces a number. Then add tracing in production so you see drift before your users complain. Treat your judge as a component you calibrate, version your prompts and datasets alongside your code, and keep folding new production failures back into the offline set.
Evaluation is not glamorous, but it is the difference between a demo and a product. The teams shipping reliable AI in 2026 are not the ones with the cleverest prompts. They are the ones who can prove, with a number that goes up and to the right, that the system is getting better instead of just different. A good eval set is also one of the highest-signal pieces of context you can build, which ties evaluation directly to context engineering. For more engineering deep dives, browse the Levelop blog or start at levelop.dev.
Frequently asked questions
What is the difference between LLM evaluation and traditional software testing?
Traditional testing asserts exact outputs for given inputs and is deterministic. LLM evaluation measures quality properties such as faithfulness, task success, and tool correctness, because language model outputs are non-deterministic and open-ended. Evaluation produces scores you track over time rather than pass-or-fail assertions, and it usually relies on graders, often other models, instead of exact-match comparisons.
What are the most important LLM evaluation metrics?
Five families cover most production needs: task completion or success rate, faithfulness or groundedness for hallucination, tool-use correctness for agents, safety for toxicity and data leakage, and latency plus cost for operational health. Choose the ones that map to how your specific system can fail rather than tracking every available metric.
Is LLM-as-a-judge reliable?
It is reliable enough to be the dominant scalable method, reaching around 80 percent agreement with human preferences at a tiny fraction of the cost, but only when you control for its biases. Judges show position, verbosity, and self-preference bias, so you must use explicit rubrics, shuffle candidate order, and calibrate against a human-labeled set. An uncalibrated judge should not be trusted as ground truth.
What is the difference between offline and online evaluation?
Offline evaluation runs against a fixed, curated dataset before you ship, which makes it reproducible and ideal for gating deploys and comparing versions. Online evaluation scores real production traffic to catch drift and failures your dataset never anticipated. Strong teams run both and feed online failures back into the offline dataset.
Which LLM evaluation tools should a small team start with?
Start with one offline framework such as DeepEval, Ragas, or promptfoo wired into continuous integration against a golden set of about fifty cases, and one observability tool such as Langfuse, LangSmith, Arize, or Braintrust for production tracing. Expand only when a real failure shows you a gap. The dataset and the feedback loop matter more than the specific vendor.