
AI Code Review: A Developer's Guide for 2026
AI code review is one of the fastest-moving shifts in software engineering right now. In early 2026, even Amazon changed its rules. After a six-hour outage on its main store in March 2026, the company told junior and mid-level engineers to get a senior sign-off before shipping AI-assisted code changes. The message was clear. AI writes a lot of code now, and someone still has to check it.
This guide explains what AI code review is, how it works, and where it helps. It also covers the limits, because they matter. If you ship code for a living, this is the workflow change worth understanding this year.
Some people call it code review AI. Others say AI code review. The terms mean the same thing. A model reads a change and gives feedback before a human merges it. Reviewing code by hand does not scale when AI writes half of it, so this practice is now part of mainstream software development.
What is AI code review?
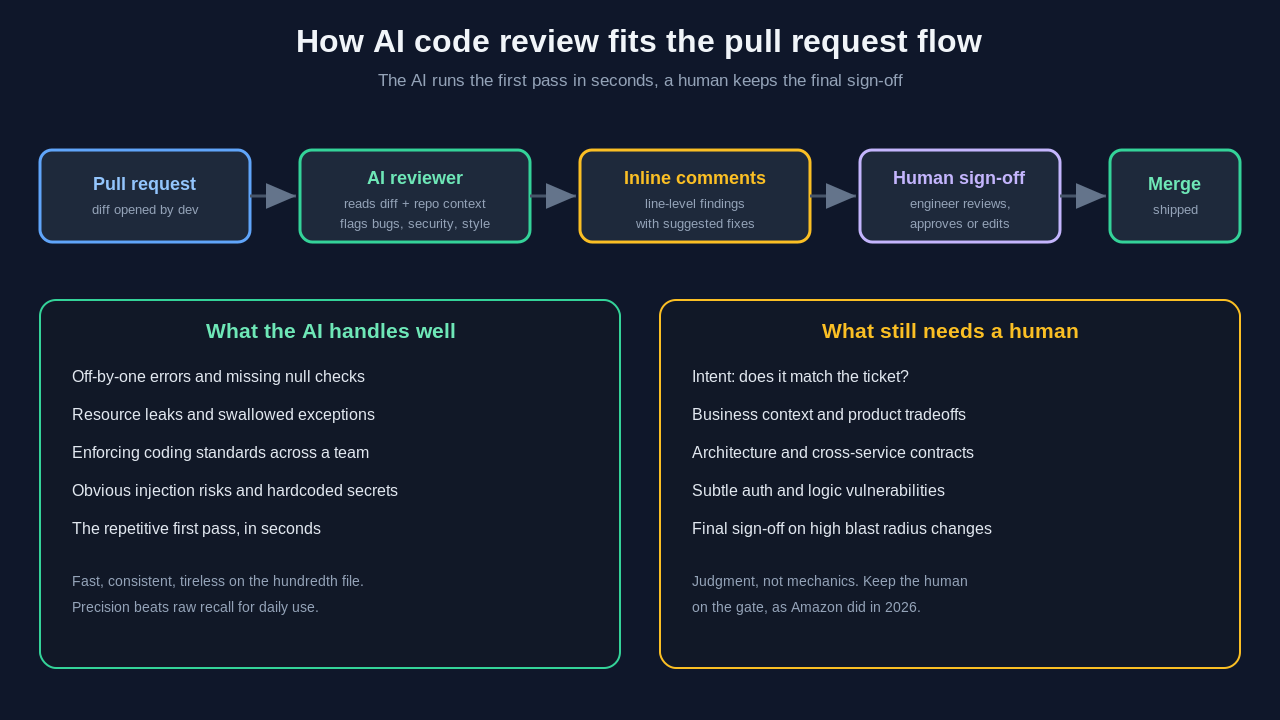
AI code review uses a large language model to read a pull request and comment on it. The model looks at your diff, and often the surrounding files, then flags bugs, security issues, and style problems. It can suggest a fix inline. Some tools can even open a follow-up change.
Think of it as a tireless first reviewer. It runs in seconds. It never gets bored on the hundredth file. A human still makes the final call, but the AI clears the easy stuff first.
This is different from older static analysis. A linter checks fixed rules. An AI code reviewer reasons about intent. It can ask why a function changed, not just whether a semicolon is missing.
Why AI code review matters now
Two things collided in 2026. AI now writes a large share of new code. And that code ships fast. Bugs ship fast too.
The Amazon case shows the risk. The outage that triggered its new rule was linked to a bad deployment. Amazon also added a 90-day reset for around 335 mission-critical systems and now requires two-person approval for major changes to them. The lesson is not that AI is bad. The lesson is that AI output needs a review gate.
This is where AI powered code review earns its place. When AI writes more, you need more review, not less. A human-only process cannot keep up with the volume. AI review scales with the code.
If you want the wider context, see our guide on what AI coding agents are and the hidden risks of vibe coding. Both explain why review has become the bottleneck.
How AI code review works
Most AI code review tools follow the same basic flow. The steps are simple. You open a pull request. The tool reads the diff and pulls in related context from your codebase. The model analyzes the change for bugs, security flaws, and quality issues. It posts comments on the exact lines, often with a suggested fix. You accept, edit, or dismiss each one.
The context step is the real difference between tools. A weak tool only sees the diff. A strong tool indexes the whole repository. That lets it spot a change that breaks something three files away.
Here is a tiny example of the kind of bug an AI reviewer catches that a linter misses.
# AI reviewer flags: off-by-one error, last item is skipped
def get_recent(items, count):
return items[len(items) - count : len(items) - 1]
# Suggested fix
def get_recent(items, count):
return items[len(items) - count :]A linter sees valid syntax. An AI reviewer sees the intent and the missing last element. That is the gap AI review fills.
Under the hood, these tools rely on the same model patterns as other agentic tools. If you are curious how that machinery works, our piece on agentic AI coding tools breaks it down.
The best AI code review tools, in brief
The market is crowded. Here is a quick read on the main names. We compare them in depth in a separate post, so this is the short version.
CodeRabbit is the precision pick. It costs around $24 per developer each month. It catches fewer bugs than some rivals but rarely wastes your time with noise. It works across GitHub, GitLab, Bitbucket, and Azure DevOps.
Greptile goes deep. It indexes your entire codebase and reasons about how a change ripples through the architecture. Independent benchmarks put its bug catch rate near 82 percent. It finds more, but it talks more too.
Qodo pairs review with testing. Qodo 2.0 launched in February 2026 with a multi-agent design. Separate agents handle bugs, security, quality, and test coverage in parallel. When it spots a coverage gap, it can write the missing test.
GitHub Copilot brings review into a tool many teams already pay for. Its code review feature scans with CodeQL and ESLint and can hand a fix to its coding agent. The catch is that review shares a capped request pool with other Copilot features.
Semgrep leans on security. It blends AI with proven static analysis to cut false positives on vulnerability findings.
What AI code review catches, and what it misses
It helps to know where these tools shine. The strengths are real, but so are the gaps.
AI review is strong on common bug classes. It spots off-by-one errors, null checks that are missing, and resource leaks. It flags a function that swallows an exception. It notices a loop that never exits. These are the mistakes that slip past a tired human at 6pm.
It is also good at consistency. It can enforce your coding standards across a large team without anyone playing style police. Name a convention once, and the reviewer applies it everywhere. That frees senior engineers to focus on design, not formatting.
Security is a mixed bag. AI review catches obvious injection risks and hardcoded secrets, including many in the OWASP Top 10. Tools like Semgrep pair the model with proven scanners to lift accuracy on vulnerability findings. But a subtle auth bug that depends on business logic can still slip through. The model does not know your threat model unless you describe it.
Now the misses. AI review struggles with intent. It cannot tell whether a change matches what the ticket actually asked for. It does not know that a slow query is fine here because the table is tiny. It cannot weigh a tradeoff against your roadmap. That judgment is the heart of senior software development, and it stays with people.
It also misses cross-cutting concerns on weaker tools. A reviewer that only reads the diff cannot see that your change breaks a contract in another service. Whole-codebase tools handle this better, but even they have blind spots. Architecture review is still a human job.
A simple rule helps here. Let the code review AI handle the mechanical pass. Let people handle meaning. When you split the work this way, both get faster and the quality goes up.
The limits you should plan for
AI code review is useful, not magic. Treat its output as a draft.
False positives are the first issue. Noisy tools flag things that are fine. Developers learn to ignore them, and then they miss the real warning. Precision matters more than raw recall for daily use.
Context blind spots are the second. The model does not know your business rules unless you tell it. It cannot judge whether a tradeoff fits your roadmap. That is human work.
Security is the third. An AI reviewer can miss a subtle logic flaw that creates a vulnerability. It can also leak code to a third-party service if you are careless about what you send. Our note on MCP security risks covers the data-flow side of AI tooling.
The Amazon rule is the right model here. AI reviews first. A human signs off. Keep the human in the loop on anything that can take down production.
How to adopt AI code review
Start small. Turn it on for one repository. Watch the comments for two weeks. Tune what the tool flags.
Then set a clear rule. Decide which changes need human sign-off no matter what the AI says. High blast radius changes always do.
Measure the noise. If your team dismisses most comments, switch tools or tighten the config. The goal is signal, not volume.
Finally, treat AI review as one layer. You still need tests, static analysis, and a human reviewer. The best AI code review tools make those people faster. They do not replace them. For more on building a modern engineering workflow, browse the Levelop blog or visit Levelop to see how we think about developer productivity.
Frequently asked questions
What is AI code review?
AI code review uses a language model to read a pull request and comment on it. It flags bugs, security issues, and style problems, and often suggests a fix. A human still approves the final change. It acts as a fast first reviewer, not a replacement for one.
Is AI code review safe to use on production code?
Yes, with a human gate. Let the AI review first, then have an engineer sign off before merge. This is the approach large teams like Amazon adopted in 2026 after AI-linked outages. Never auto-merge AI-approved changes to critical systems.
What are the best AI code review tools in 2026?
Popular options include CodeRabbit for precision, Greptile for deep codebase context, Qodo for review plus test generation, GitHub Copilot for teams already in that ecosystem, and Semgrep for security. The right pick depends on your stack, budget, and how much noise your team tolerates.
Can AI code review replace human reviewers?
No. AI handles the repetitive first pass well. It cannot judge business context, product tradeoffs, or whether a design fits your long-term plan. The strongest setup pairs an AI reviewer with a human who makes the final decision.
How is AI code review different from a linter?
A linter checks fixed rules, like formatting and unused variables. An AI code reviewer reasons about intent and context. It can catch a logic bug that a linter sees as valid syntax, and it can explain why the change is risky.
The bottom line
AI code review moved from novelty to standard practice in 2026. When AI writes more code, you need a faster way to check it. The tools are good and getting better. The smart play is to use AI review as your first pass and keep a human on the gate. That balance, speed from the machine and judgment from the person, is what Amazon landed on. It is a good rule for the rest of us too. For more developer guides, visit the Levelop blog.