
Best AI Code Review Tools in 2026: CodeRabbit vs Greptile vs Qodo vs Copilot
Picking the best AI code review tools in 2026 is harder than it sounds, because there are now a dozen credible options and every one of them claims to catch the most bugs. The truth is messier. Each tool makes a different tradeoff between how much it finds, how much noise it creates, and how much it costs. This guide compares the four names that come up most often, CodeRabbit, Greptile, Qodo, and GitHub Copilot, plus Semgrep for teams that care most about security.
The stakes went up this year. After a six-hour outage on its main store in March 2026, Amazon told junior and mid-level engineers to get a senior sign-off before shipping AI-assisted code. When a company that size adds a review gate, the rest of the industry pays attention. AI writes a large share of new code now, and someone still has to check it before it reaches production.
If you want the foundational background first, our pillar guide explains what AI code review is and how it works. This post is the deep comparison it points to. We will look at real pricing, independent benchmarks, the strengths and the blind spots of each tool, and finish with a simple way to choose. By the end you should know which AI code review tool fits your stack, your budget, and your team's tolerance for noise.
New to the topic? Start with our developer's guide to AI code review, then come back here for the head-to-head.
How we compared the best AI code review tools
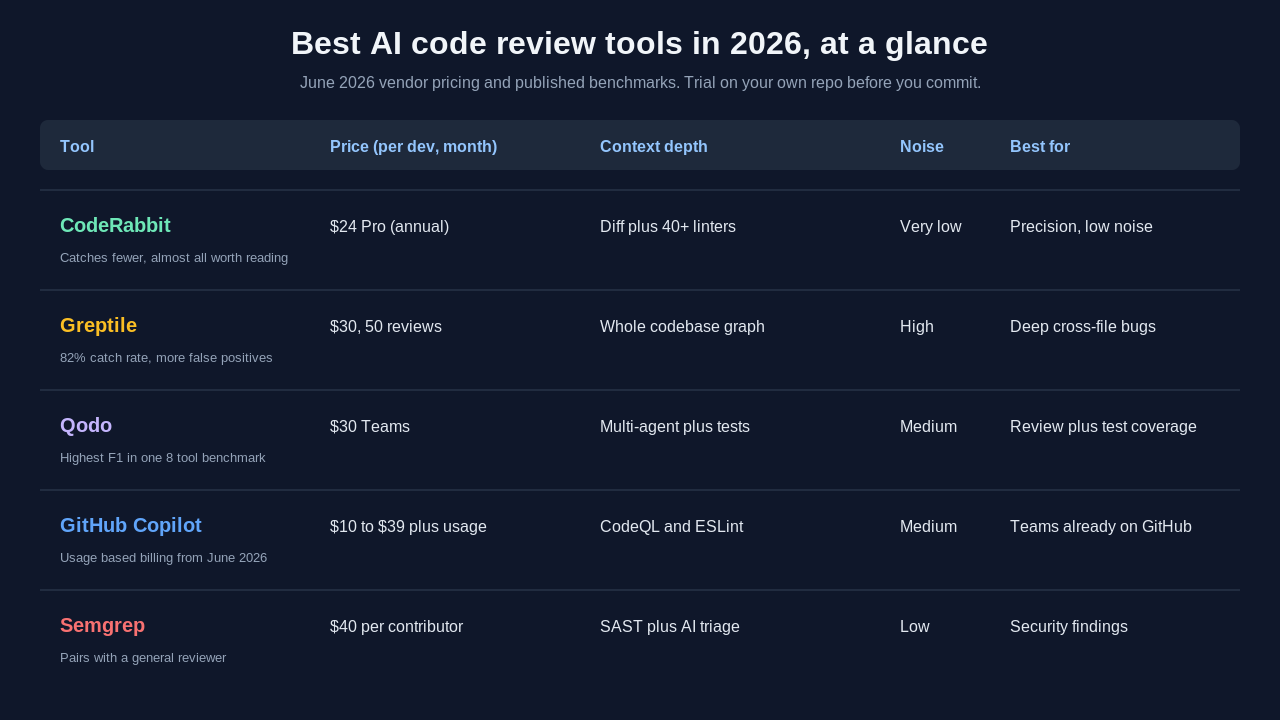
We looked at four things for each tool: pricing as of June 2026, how it gathers context, what it catches in independent testing, and how much noise it generates. Pricing came from each vendor's public page. Benchmark numbers came from published comparisons, and that is where you need to be careful.
With that caveat in place, a few patterns hold across most tests. Greptile catches the most bugs in a single pass but produces the most false positives. CodeRabbit catches fewer but rarely wastes your time. Qodo's multi-agent design posts strong accuracy scores and adds test generation. Copilot brings review into a tool many teams already pay for. Semgrep leads on security findings. Those tradeoffs, not a leaderboard, should drive your choice.
CodeRabbit: the precision pick
CodeRabbit is the tool to beat for signal-to-noise. Its Pro plan runs about 24 dollars per developer each month on annual billing, or 30 dollars month to month, with a Pro Plus tier at 48 dollars that adds unit test generation. Billing is per seat, and only developers who open pull requests count, so a large team with a few active committers pays less than the headcount suggests.
On context, CodeRabbit pairs its language model with more than 40 linters and static analysis tools. It reviews across GitHub, GitLab, Bitbucket, and Azure DevOps, posts inline comments, and can apply autofixes. In February 2026 it added an Issue Planner that connects to Linear, Jira, and GitHub Issues, so review feedback can flow straight into your backlog.
The standout trait is restraint. In one independent test of 118 self-contained runtime bugs, CodeRabbit detected around 46 percent of them while producing only two false positives across the run. That is a lower raw catch rate than Greptile, but the comments your developers see are almost always worth reading. A reviewer your team trusts is a reviewer your team will actually use.
The weakness is the flip side. If you want maximum recall, the tool that flags every possible issue, CodeRabbit will miss things that a noisier tool catches. For most teams that is the right trade. For a security-critical codebase where a miss is expensive, you may want a second layer.
Greptile: the deep-context pick
Greptile takes the opposite bet. It builds a graph index of your entire codebase, then sends a swarm of AI agents to review each pull request with full architectural context. Its pricing is 30 dollars per seat each month with 50 reviews included, and additional reviews at one dollar each. Pre-Series A startups with under two million dollars in revenue get 50 percent off.
The per-review pricing is unusual and worth flagging. Most rivals charge a flat seat fee with unlimited reviews. Greptile meters past the included 50, so a high-volume team needs to model the overage. The upside is the depth. Because Greptile understands dependencies across files, it catches a change that breaks something three modules away, the kind of bug a diff-only reviewer never sees.
On raw detection, Greptile reported an 82 percent bug catch rate on its own benchmark, well ahead of the diff-only tools it tested against. The cost of that recall is noise. The same class of testing showed Greptile generating roughly 11 false positives where CodeRabbit produced 2. The company raised a Series A led by Benchmark in 2026 at a 180 million dollar valuation, so it has the funding to keep pushing the catch rate up while it works on precision.
If your reviews keep missing cross-cutting issues, deep context is the feature that fixes it. To understand why whole-codebase reasoning beats a diff-only pass, our explainer on how agentic AI coding tools work covers the indexing and retrieval machinery underneath.
Qodo: review plus test generation
Qodo, formerly Codium, is the tool that pairs review with testing. Its Teams plan is 30 dollars per user each month on annual billing, or 38 dollars monthly, with a free Developer tier that includes 30 pull request reviews plus 250 IDE and CLI credits a month. A managed Qodo Merge Pro tier adds an enterprise context engine and SOC 2 compliance.
The big change was Qodo 2.0, released in February 2026 with a multi-agent architecture. Instead of one general model trying to catch everything, separate agents run in parallel: one for bugs, one for security, one for code quality, and one for test coverage. Each agent has prompts tuned to its job. In one comparative benchmark of eight tools, that design posted the highest F1 score at 60.1 percent, the metric that rewards catching real issues while penalizing false alarms.
Test generation is the feature that sets Qodo apart from a pure reviewer. When it spots a coverage gap, it can write the missing test. Select a function, run the test command, and Qodo produces a test file in seconds. For teams bootstrapping coverage on a legacy codebase, that workflow can generate dozens of tests a day with moderate human cleanup.
Here is the kind of bug a coverage agent surfaces, then backs up with a generated test that would have caught it.
# Qodo flags: empty input is unhandled, this raises ZeroDivisionError
def average(scores):
return sum(scores) / len(scores)
# Generated test that exposes the gap
def test_average_empty():
with pytest.raises(ValueError):
average([]) # expect a clear error, not a crashGitHub Copilot code review: the in-ecosystem pick
GitHub Copilot brings review into a tool many teams already pay for. Plans run from a free tier to Pro at 10 dollars, Pro Plus at 39 dollars, Business at 19 dollars per user, and Enterprise at 39 dollars per user each month. The code review feature scans pull requests for logic bugs and maintainability issues and can hand a fix to the Copilot coding agent.
Pricing changed in a way you need to plan for. On June 1, 2026, Copilot moved to usage-based billing, swapping premium requests for a monthly allotment of AI Credits at one cent each. From that date, code review also consumes GitHub Actions minutes on top of credits. So the headline seat price is not the whole cost. Heavy review usage can run over the allotment, with overage at four cents per premium request.
On capability, Copilot reached 60 million code reviews by March 2026, a tenfold jump since its launch a year earlier, so it is battle-tested at scale. Security comes through CodeQL, with ESLint and PMD findings layered in. The nuance is that CodeQL runs as a separate scan rather than the AI reasoning about security itself, so for deep vulnerability analysis a dedicated tool still does more.
If your team already lives in GitHub and uses Copilot for completions, turning on review is the path of least resistance. For a wider look at how Copilot stacks up against other assistants, see our comparison of Claude Code and Cursor.
Semgrep: the security pick
Semgrep is not a general code reviewer, it is a security platform with an AI assistant on top, and that focus is the point. Pricing is around 40 dollars per contributor each month, counting developers who make commits. It blends proven static analysis with AI to cut the false positives that make most security scanners painful to live with.
The numbers Semgrep publishes are about triage, not catch rate. Its assistant auto-handles roughly 60 percent of incoming security triage when its memory feature is enabled, and it agrees with human security researchers on true positives about 96 percent of the time. Teams report triaging far fewer false positives once it is on. If your bottleneck is a security team drowning in scanner noise, that is the problem Semgrep solves.
Security is also where general AI reviewers are weakest. They catch obvious injection and hardcoded secrets, but a subtle authorization flaw that depends on business logic slips past. Pairing a general reviewer with a security-focused tool covers both. For the data-flow risks of sending code to any AI service, our note on MCP security risks is worth a read.
How to choose the best AI code review tool for your team
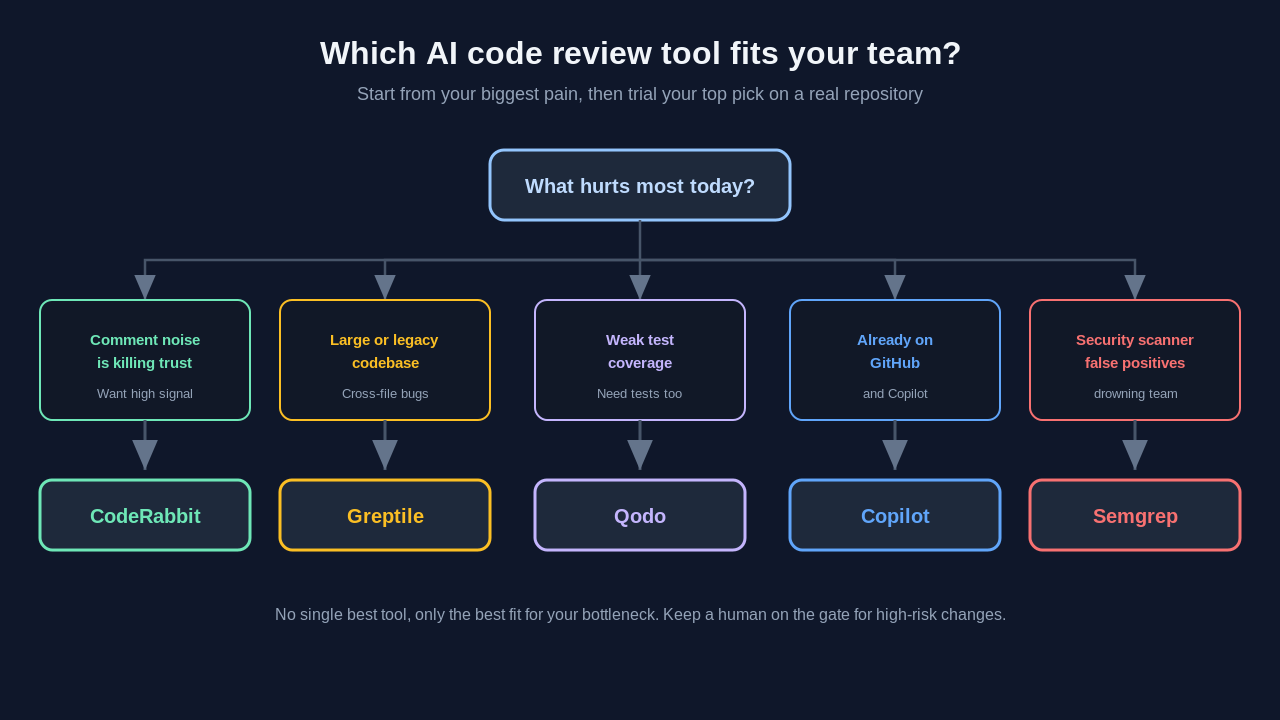
The right pick depends on what hurts most today. Use this as a starting filter, then trial your top one or two on a real repository before you commit.
- Want the least noise and high trust: choose CodeRabbit. It catches fewer issues but almost never wastes a developer's time.
- Have a large or legacy codebase with cross-file bugs: choose Greptile for whole-codebase context, and budget for the per-review pricing.
- Need review and better test coverage together: choose Qodo, whose multi-agent reviews also generate the tests you are missing.
- Already standardized on GitHub and Copilot: turn on Copilot code review, and watch the usage-based billing.
- Drowning in security scanner false positives: add Semgrep alongside a general reviewer rather than replacing it.
One more rule matters more than any feature list. Do not pick the tool that catches the most. Pick the one your team will actually read. A reviewer your developers learn to ignore is worse than no reviewer at all, because it trains them to dismiss warnings, including the real ones. Precision beats raw recall for daily use.
Whichever tool you choose, treat it as one layer. You still need tests, static analysis, and a human on the gate for anything that can take down production. The best AI code review tools make those people faster, they do not replace them. Once a tool is in production, you will also want to watch how it behaves over time, which is where observability for AI agents comes in.
Frequently asked questions
What are the best AI code review tools in 2026?
The most credible options are CodeRabbit for precision and low noise, Greptile for whole-codebase context, Qodo for review plus test generation, GitHub Copilot for teams already in that ecosystem, and Semgrep for security. The best one depends on your stack, budget, and how much noise your team tolerates.
Which AI code review tool catches the most bugs?
Greptile reports the highest single-pass catch rate, around 82 percent on its own benchmark, because it indexes the whole codebase. The tradeoff is more false positives. CodeRabbit catches fewer but produces far less noise. Remember that vendor benchmarks favor the vendor, so trial tools on your own code.
How much do AI code review tools cost?
As of June 2026, CodeRabbit Pro is about 24 dollars per developer per month on annual billing, Greptile is 30 dollars per seat with 50 reviews included, Qodo Teams is 30 dollars per user, Semgrep is around 40 dollars per contributor, and GitHub Copilot ranges from 10 to 39 dollars per user with usage-based billing on top.
Is CodeRabbit or Greptile better?
It depends on your priority. CodeRabbit is the precision pick: fewer comments, almost all worth reading. Greptile is the depth pick: it catches more cross-file bugs but generates more false positives. Choose CodeRabbit to avoid comment fatigue, and Greptile for large or legacy codebases where hidden bugs are costly.
Can AI code review tools replace human reviewers?
No. AI handles the repetitive first pass well, but it cannot judge business context, product tradeoffs, or whether a design fits your long-term plan. The strongest setup pairs an AI reviewer with a human who makes the final call, the approach large teams like Amazon adopted in 2026.
The bottom line
The market for AI code review tools is crowded, but the choice is simpler than the marketing suggests. CodeRabbit wins on trust, Greptile on depth, Qodo on tests, Copilot on convenience, and Semgrep on security. None of them removes the need for a human on the gate. Pick the one that fixes your biggest bottleneck, run a two-week trial, and tune what it flags. For more developer guides, visit the Levelop blog or explore Levelop to see how we think about developer productivity.