
Why Levelop Teaches 12 Coding Interview Patterns Instead of 2500 Problems
I built Levelop around a decision that sounds, on first hearing, like a confession of laziness. We teach twelve coding interview patterns. Not five hundred problems. Not two thousand. Twelve. People ask me how a platform can be serious about interview prep when the popular wisdom is to grind through every problem you can find. This post is the long answer, written as the founder, about why fewer is the harder and better path, and why the obsession with raw problem count quietly wastes most of the time people pour into it.
I am not neutral here, obviously. I have a product that reflects this belief. But the belief came first, out of my own failures, and the product is downstream of it. So let me show you the reasoning rather than just assert the conclusion.
The math nobody does before they start grinding
LeetCode has well over 3000 problems now. The folk advice floating around forums lands somewhere around "do 2500 to be safe," or at minimum the famous "Blind 75" expanded into a few hundred. Let me do the arithmetic that almost nobody does before they commit.
Say you can genuinely work a medium problem, including reading the editorial, understanding the optimal solution, and writing it cleanly, in about 35 minutes. That is optimistic. At 2500 problems, you are looking at roughly 1450 hours. If you study two focused hours a day, every single day with no breaks, that is two years. Most people quit long before, not because they are weak, but because the plan was never finishable in the first place.
The deeper problem is not the hours. It is what those hours buy you. If you solve 2500 problems by grinding without a frame, you are mostly building a giant, brittle lookup table in your head: this exact problem maps to this exact solution. The first time an interviewer reskins the problem, the lookup misses, and you freeze. I know because I did exactly this, and I wrote the whole painful story up in how four failed FAANG interviews led me to rebuild my prep from scratch.
What expertise research actually says about chunking
Here is the part that changed how I thought about all of it. There is a body of cognitive science going back to the 1960s on how experts differ from novices, and it does not say experts have memorized more individual facts. It says they have better chunks.
The classic study is De Groot's work on chess masters, later sharpened by Chase and Simon at Carnegie Mellon. They showed chess positions to masters and to beginners for a few seconds, then asked them to reconstruct the board. On real game positions, masters reconstructed almost perfectly while beginners struggled. The obvious conclusion is that masters have better memory. But then the researchers showed the same people randomly arranged pieces that could never occur in a real game. The masters' advantage almost completely vanished. Their edge was never raw memory. It was that real positions decomposed into familiar chunks, recognizable patterns of pieces that they had internalized over years.
Coding interviews work the same way. A strong engineer does not see "Problem 1438" and recall a stored answer. They see a problem and notice, almost instantly, that the constraint is monotonic, which is the tell for binary search on the answer, or that they need the maximum in a shifting range, which is the tell for a monotonic structure. The problem decomposes into known chunks. That recognition is the entire skill, and it is exactly what raw grinding fails to build, because grinding optimizes for the surface story of each problem rather than its underlying structure.
If interview skill is really about a compact library of reusable chunks, then the right unit of study is the chunk, not the problem. The problem is just one of a thousand costumes the chunk can wear. This is the whole case for coding interview patterns over problem count, compressed into a sentence.
So why exactly twelve
The popular pattern lists are not wrong to exist, they are just oddly sized. The well-known educative.io piece 14 patterns to ace any coding interview and the Grokking the Coding Interview course that grew out of it proved the idea works at scale. I owe them a debt for popularizing pattern-based prep. My quibble is with calibration, not direction.
I landed on twelve after mapping a few thousand real interview problems back to their underlying technique and watching where the distribution actually concentrated. A small set of patterns covers the overwhelming majority of what gets asked. Past about a dozen, you hit sharply diminishing returns: the thirteenth and fourteenth patterns show up rarely, and when they do, they tend to be a combination of two patterns you already know rather than something genuinely new.
Here is the set we teach, and notice that several of them already have full breakdowns on the blog:
THE 12 CODING INTERVIEW PATTERNS
1. Two Pointers opposite or same-direction scanning
2. Sliding Window a contiguous range that grows and shrinks
3. Prefix Sum precompute once, answer range queries in O(1)
4. Binary Search on sorted data, and on the answer itself
5. DFS / Backtracking explore every branch, undo, try the next
6. BFS shortest path and level-by-level exploration
7. Trees recursion where the return value is the trick
8. Dynamic Programming define a state, define a transition
9. Greedy when the local choice is provably global
10. Heap / Top-K "give me the best one" in O(log n)
11. Monotonic Stack each element's nearest greater or smaller
12. Intervals sort by start, then scan and merge
~2500 problems -> 12 patterns -> the same 12 chunks, reusedA few of these lean on a core data structure rather than a standalone trick. Binary search needs sorted arrays and is really just finding the middle of a range and halving it. Breadth first search (BFS) and depth first search (DFS) walk a graph level by level or branch by branch. A heap, a monotonic stack, a hash map, even a humble linked list are the data structures that make these interview patterns work. Learn the structure and the interview problems built on top of it stop looking unfamiliar.
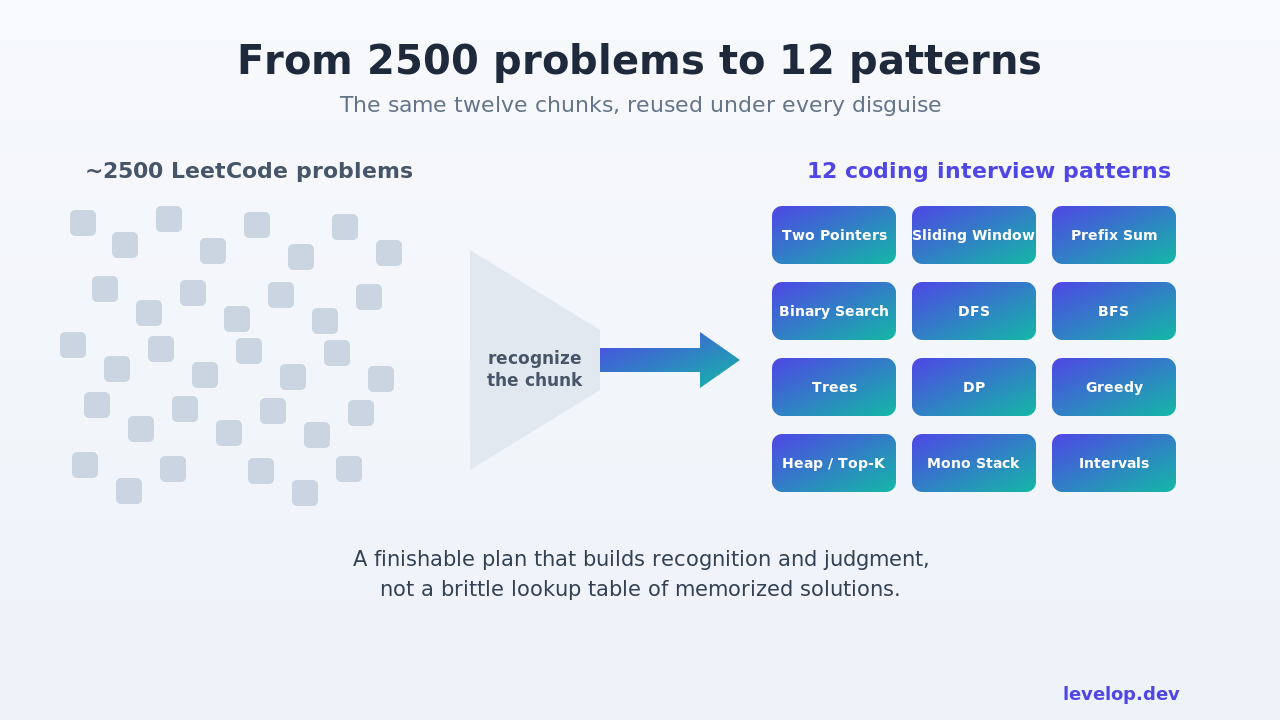
The point of the table is not the exact list. Reasonable people draw the boundaries slightly differently, and that is fine. The point is the collapse. Two thousand five hundred costumes, twelve actors underneath.
What changes in your head when you study patterns instead of problems
The difference is not that you stop solving problems. You still solve plenty. The difference is what each problem is for. When I grind problems, each one is a destination. When I study a pattern, each problem is evidence about a pattern, a single data point that sharpens my sense of when this technique fires and when it does not.
Take dynamic programming. You can do two hundred DP problems and still feel shaky, because you have been treating each as a fresh puzzle. Or you can internalize the actual move, which is that DP is about finding a state and a transition, not memorizing solutions, and then solve fifteen problems specifically to feel how that one idea bends across cases. The second engineer, with fifteen problems, will out-interview the first with two hundred almost every time. I have watched it happen in our own data.
The same compression shows up everywhere. Once the sliding window pattern clicks, a whole family of O(n^2) problems collapses into O(n) and you stop seeing them as separate. Once two pointers reveals itself as the structure hiding inside sorted-array problems, a dozen "different" questions become one question. I wrote up the cleanest version of this collapse in solving three DP problems with the exact same template, because the template is the chunk made visible.
There is also a judgment layer that only patterns can teach. Knowing twelve techniques means the real skill becomes choosing among them, and choosing is where interviews are won or lost. I learned this the embarrassing way, reaching for dynamic programming on problems a greedy approach solved in three lines, which became its own post on five greedy problems where I wrongly reached for DP first. You cannot develop that judgment by grinding, because grinding never forces you to pick. The answer key already picked for you.
The strongest objection, stated honestly
I want to give the other side its best shot, because a one-sided manifesto is just marketing.
The serious objection goes like this: top companies deliberately design problems that resist pattern matching. They twist the setup precisely so that a candidate who only recognizes templates gets stuck. If you train recognition, you are training the exact reflex the hardest interviews are built to defeat. And there is real truth in it. The trend toward companies asking you to explain code rather than just produce it, and more broadly toward AI reshaping what the coding interview even tests, means pure pattern-spotting is necessary but no longer sufficient.
Here is where I think the objection actually points, though. It is not an argument against patterns. It is an argument against shallow patterns. The failure mode it describes, freezing when a problem is reskinned, is exactly what happens when someone memorizes the surface of a pattern without understanding why it works. The fix is not to abandon patterns and return to grinding two thousand problems. That makes the brittleness worse, not better. The fix is to learn the twelve patterns deeply enough that you can recognize them in disguise and combine them under pressure.
A senior interviewer is not testing whether you can name a pattern. They are testing whether you can take a novel problem, decompose it into the patterns you know, notice that this one needs a binary search nested inside a greedy choice, and reason out loud while you do it. That skill is built on a small set of deeply held patterns plus a lot of practice combining them. It is not built on volume.
How we actually teach twelve patterns without making it shallow
Skepticism here is fair, so let me be concrete about how Levelop tries to avoid the shallow trap, including the parts that are still hard.
Each pattern is taught from its underlying idea first, not its template. Before you see any code for sliding window, you should be able to say in plain language what invariant the window maintains and why that lets you avoid recomputing. Then you solve a deliberately varied spread of problems for that pattern, including ones where the pattern almost fits but does not, because the negative examples teach the boundary of when it applies. Then you are pushed to combine patterns, because that combination is the actual interview.
Some of the philosophy behind this came directly out of building our AI mentor, and the surprising lessons about how engineers actually learn to code. The short version is that a clear explanation handed over at the wrong moment teaches almost nothing, and that productive struggle is the feature rather than the bug. A pattern you fought to recognize sticks. A pattern handed to you on a slide evaporates by next week.
GRIND MODEL PATTERN MODEL
problem -> answer key problem -> "which chunk is this?"
problem -> answer key recognize -> apply -> note the tell
problem -> answer key vary it -> find where it breaks
(x2500, then hope) combine chunks under pressure
builds a lookup table builds recognition + judgmentI will not pretend the count is sacred. If a thirteenth pattern earned its place by showing up often enough, we would add it, and we periodically revisit the boundaries against fresh interview data. Twelve is the current honest answer to "what is the smallest set that covers the most ground," not a number I am married to. The principle is less, taught deeply. The exact figure is just where the evidence currently sits.
Where the pattern approach genuinely falls short
To keep myself honest, the limits. Patterns get you through the algorithmic round, but they do almost nothing for system design, where the skill is reasoning about tradeoffs at scale rather than recognizing a technique. They do not cover the behavioral round, which eliminates more senior candidates than people admit. And for a true research-grade problem, the kind that is genuinely novel rather than reskinned, twelve patterns give you a starting vocabulary but not a guaranteed path. You still have to think.
So if someone tells you patterns are a complete interview strategy, they are overselling. Patterns are the highest-leverage component of the algorithmic portion, full stop. That is a big claim but a bounded one, and I would rather make a bounded claim that holds than a sweeping one that does not.
The case for less
Strip away the product and the manifesto and what is left is a simple bet. Mastery is compression, not accumulation. The expert is not the person who has seen the most problems. It is the person who sees the fewest distinct things, because so much of what looks different to a beginner has collapsed, in their head, into the same handful of patterns.
Twelve coding interview patterns, understood deeply enough to recognize in disguise and combine under pressure, is a finishable plan that builds the thing interviews actually test. Two thousand five hundred problems, ground without a frame, is an unfinishable plan that builds a lookup table. I picked less on purpose, and after watching thousands of engineers move through both approaches, I would pick it again.
Where this comes from
This philosophy is the backbone of how we built Levelop, and it grew directly out of my own failed interviews and a year of watching how engineers actually learn. If you want the origin story, it is in the post about failing four FAANG interviews and building a platform to fix the process.
Frequently asked questions
Is twelve patterns really enough to pass a FAANG coding interview?
For the algorithmic rounds, a deeply understood set of around twelve patterns covers the large majority of what gets asked, especially once you can recognize a pattern in disguise and combine two of them. It is necessary but not sufficient for the whole loop, since system design and behavioral rounds test different skills entirely. The pattern set is the highest-leverage piece of the coding portion, not the entire interview.
Coding interview patterns vs problems: should I stop doing LeetCode problems?
No, you should change what each problem is for. Keep solving problems, but treat each one as evidence about a pattern rather than a destination to memorize. A focused spread of fifteen to twenty problems per pattern, including cases where the pattern almost fits but fails, builds far more durable skill than grinding hundreds of unframed problems.
How is this different from Grokking the Coding Interview or the 14 patterns list?
The direction is the same and I credit those resources for popularizing pattern-based prep. The difference is calibration and depth. I argue for a slightly smaller set taught from the underlying idea first, with deliberate negative examples and an explicit focus on combining patterns, because shallow pattern matching fails the same way memorization does.
Won't interviewers just give me a novel problem that no pattern covers?
They will try, and that is exactly why depth matters. Truly novel problems are usually a combination of patterns you already know, wearing an unfamiliar story. Deeply held patterns plus practice decomposing and combining them is what gets you through a reskinned problem, whereas memorized templates are what freeze.
How long does it take to learn the twelve patterns?
Most engineers can get a working grasp of all twelve in a focused six to eight weeks, versus the roughly two years that grinding 2500 problems would take at two hours a day. The pattern path is finishable, which is half of why it works, because a plan you actually complete beats a better plan you abandon.