
Spec-Driven Development in 2026: The Complete Guide for Developers
Spec-driven development is the methodology that finally answered the question every engineering team asked in 2025: how do we get the speed of AI coding agents without the chaos? I spent the last few months moving Levelop's own workflows from prompt-and-pray to spec-first development, and this guide is everything I wish someone had handed me at the start.
If you have been coding with AI agents for a while, you already know the pattern. The first 80% of a feature appears in minutes. Then you spend three days untangling what the agent actually built, because what you meant and what you typed were two different things. Spec-driven development (SDD) exists to close that gap.
What Is Spec-Driven Development?
Spec-driven development is a workflow where a written, structured specification becomes the source of truth for what you are building, and AI coding agents derive the implementation, tests, and documentation from that spec. You describe the what and the why in detail before any code gets generated. The spec is not throwaway documentation. It is an executable artifact that drives the whole loop.
That ordering is the entire trick. In traditional AI-assisted coding, the prompt is disposable and the code is the artifact. In spec-driven AI development, the spec is the artifact and the code is almost a build output. When requirements change, you update the spec and re-derive, instead of archaeology-digging through 40 chat turns to figure out what you asked for.
A reasonable reaction here is "so we reinvented waterfall?" Not quite, and I was skeptical too. Waterfall failed because specs were written once, by people far from the code, and drifted from reality within weeks. SDD specs are written next to the code, versioned in the same repo, and cheap to regenerate against. The feedback loop is hours, not quarters.
Why Vibe Coding Hit a Wall
To understand why spec-driven development took over 2026, you need to understand what it replaced. Vibe coding, the improvise-with-an-agent style that Andrej Karpathy named in early 2025, was genuinely great for prototypes. I wrote about that workflow in our vibe coding guide, and I still reach for it when I'm exploring an idea.
The problem showed up around month three of any serious project. AI-generated code that nobody specified becomes code that nobody owns. Simple modifications turn into troubleshooting sessions. We covered the security and quality side of this in the hidden risks of vibe coding, but the deeper issue is architectural: with no spec, every prompt is a tiny act of redesign, and a thousand tiny redesigns produce a system with no design at all.
Even Karpathy called the shift. One year after coining the term, he declared the vibe coding era effectively over and described the new default as agentic engineering: you stop writing most of the code directly and instead orchestrate agents against detailed intent, with real oversight. His framing of "agentic" is that you are not typing the code 99% of the time, and "engineering" is the reminder that doing this well is a skill. The New Stack has a good write-up of that shift.
Agentic engineering needs something for the agents to be engineered against. That something is the spec.
How Spec-Driven Development Actually Works
Every SDD tool implements roughly the same loop, with different names. Here is the canonical version, using the phase names from GitHub's Spec Kit since they have become the de facto vocabulary.
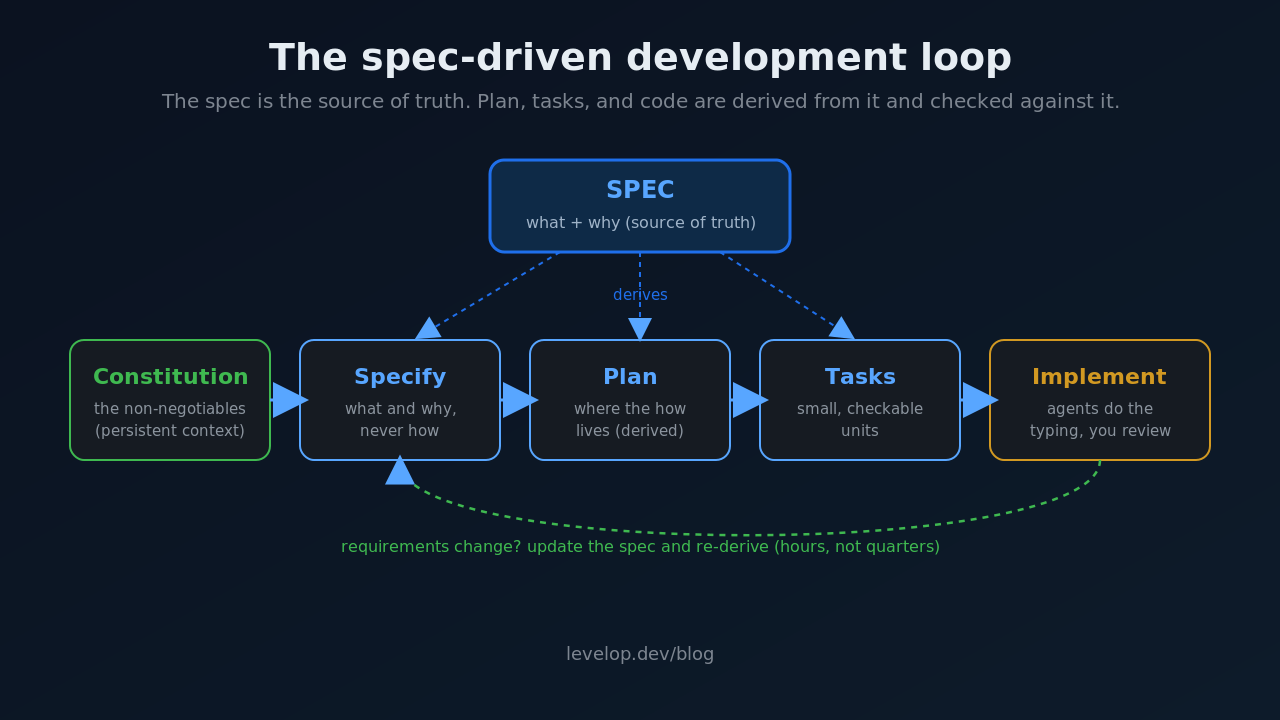
1. Constitution: the non-negotiables
Before any feature work, you write down the rules that apply to everything: stack choices, testing requirements, performance budgets, security constraints, naming conventions. This is the project's constitution. Agents read it on every run, which means you stop repeating "we use Postgres, not Mongo, stop suggesting Mongo" in every session.
# constitution.md (excerpt)
## Non-negotiables
- TypeScript strict mode. No `any` without an inline justification comment.
- Every API route ships with an integration test in the same PR.
- Postgres via Drizzle. No raw SQL outside /db/migrations.
- p95 API latency budget: 300ms. Flag any design that risks it.2. Specify: what and why, never how
You describe the feature in terms of user outcomes: who it is for, what success looks like, edge cases, what is explicitly out of scope. The discipline here is leaving implementation out. The moment your spec says "use a Redis sorted set," you have stopped specifying and started coding badly in English.
3. Plan: where the how lives
The agent (with your review) derives a technical plan from the spec plus the constitution: data models, interfaces, contracts, migration steps. This is the document where "Redis sorted set" belongs. Because the plan is derived, you can throw it away and re-derive when the spec changes, without touching the spec.
4. Tasks: small, checkable units
The plan gets decomposed into atomic tasks, each independently implementable and verifiable. This is what makes agent work reviewable. Instead of one 3,000-line diff, you review 18 focused changes that each map back to a named requirement.
5. Implement: agents do the typing
Only now does code get generated, task by task, with the spec and constitution in context the whole time. Your job shifts to review and steering. In my experience this is where SDD quietly fixes code review too: you are no longer reviewing "did the agent write good code" in a vacuum, you are checking diffs against a spec you already agreed on.
The Spec-Driven Development Tools Landscape in 2026
The spec driven development tools space exploded over the past year. Practically every major vendor shipped an SDD flavor. These are the three I have spent real time with, plus what else is out there.
GitHub Spec Kit
Spec Kit is an open-source toolkit that brings the full SDD loop to the agent you already use: it works with Copilot, Claude Code, Cursor, Codex, Gemini CLI, and more. You bootstrap a project with the `specify` CLI, then drive the loop with slash commands inside your agent chat:
# Bootstrap a project with Spec Kit
uvx --from git+https://github.com/github/spec-kit.git specify init my-project
# Then, inside your coding agent:
# /speckit.constitution -> project principles
# /speckit.specify -> feature spec (creates specs/001-feature/spec.md)
# /speckit.plan -> technical plan
# /speckit.tasks -> actionable task list
# /speckit.implement -> execute the tasksEach feature gets its own numbered directory under `specs/`, with the spec, plan, and tasks as versioned markdown files. It is agent-agnostic, which made it the easiest on-ramp for us, and the quickstart docs get you to a first spec in about ten minutes. Microsoft's developer blog has a solid hands-on walkthrough if you want a guided tour.
AWS Kiro
Kiro is AWS's agentic IDE built around specs as the primary interface. Instead of bolting specs onto a chat workflow, Kiro generates requirements (in EARS notation), design documents, and task lists as first-class IDE objects, and keeps them in sync as you work. It is the most opinionated of the three, which is either its best or worst feature depending on how much you like opinions. If your team lives on AWS already, it is the obvious one to evaluate.
OpenSpec
OpenSpec is the lightweight open-source option: a spec-driven workflow you can drop into an existing repo without adopting a new IDE or CLI-heavy ceremony. It tracks change proposals as diffs against current specs, which maps nicely onto how teams actually evolve systems. We use ideas from it even where we run Spec Kit.
Beyond those three: Claude Code supports spec-driven workflows natively through CLAUDE.md plus plan mode, Tessl is building a spec-as-source platform where the spec literally replaces code as the maintained artifact, and BMAD layers agile-flavored roles on top of the same loop. The methodology matters more than the tool. Pick one, run two features through it, and you will know what you need.
A Practical Example: One Feature, Spec-First
Here is a compressed version of a real spec from our codebase, for a streak-freeze feature in Levelop's practice tracker. This is the level of specificity that makes the loop work:
# spec: streak freeze
## Why
Learners lose motivation when a single missed day resets a 40-day streak.
Streak freezes (1 per 7-day window) preserve momentum without making
streaks meaningless.
## Acceptance criteria
- A learner with >= 7 consecutive active days earns 1 freeze (max 2 banked).
- A missed day consumes a freeze automatically at 00:00 in the learner's
timezone, not UTC.
- Freeze consumption is visible in the activity log within 5 seconds.
- A learner with 0 freezes and a missed day resets to 0 (current behavior).
## Out of scope
- Purchasing freezes. Gifting freezes. Retroactive freezes.From that spec, the plan derived a schema change (two columns, one backfill migration), an event consumer, and a timezone edge-case matrix. The tasks phase produced 11 tasks. The implementation ran with me reviewing diffs against acceptance criteria instead of guessing at intent. Total wall-clock time was about a day, and two months later a new contributor changed the banking limit by editing one line of the spec and re-deriving.
The contrast with our pre-SDD workflow is not subtle. The same class of feature used to generate a week of back-and-forth, because the requirements lived in my head and leaked out one prompt at a time.
When Spec-First Development Is Overkill
An honest guide has to say this part out loud: spec-first development is not free. Writing a real spec costs an hour or three. For some work, that is pure waste.
Skip the spec when you are prototyping to learn (the code is disposable by design), when the change is genuinely trivial, or when you are exploring an API surface and do not yet know what you want. That is still vibe coding territory, and that is fine. I keep both modes and switch consciously.
Reach for the spec when more than one person (or more than one agent session) will touch the work, when the feature has real edge cases, when it touches money, auth, or data migrations, or when you know requirements will evolve. The rule of thumb I give our team: if you would write a ticket longer than two sentences for a human, write a spec for the agent.
SDD and Context Engineering Are the Same Discipline
If you have read our context engineering guide, this framing will feel familiar, because spec-driven development is context engineering applied at the feature level. A spec is the highest-density context object you can hand an agent: it compresses intent, constraints, and acceptance criteria into the exact form a model can act on. The constitution is persistent context; the spec is task context. The best practices we documented for context engineering (curate ruthlessly, structure over prose, keep the source of truth in the repo) are exactly the practices that make specs work.
That is also why SDD pairs so well with capable AI coding agents: the better the agent, the more leverage a precise spec buys you. Garbage spec, garbage feature, faster than ever.
FAQ
What is spec-driven development in simple terms?
Spec-driven development is a way of building software where you write a detailed specification of what you want before AI agents generate the code. The spec describes user outcomes, acceptance criteria, and constraints. The plan, tasks, implementation, and tests are all derived from it and checked against it. The spec stays in your repo as the source of truth, so changing the software starts with changing the spec.
Is spec-driven development just waterfall again?
No. Waterfall separated specification from implementation by months and by team, so specs drifted from reality. In SDD the spec lives in the repo, the derive-implement-verify loop runs in hours, and updating the spec is the normal way to change the system. It keeps waterfall's clarity of intent and throws away the part that failed, the long feedback loop.
Which spec-driven development tool should I start with?
Start with GitHub Spec Kit if you want something agent-agnostic that works with Copilot, Claude Code, or Cursor today. Evaluate AWS Kiro if you want a full IDE built around specs and you are already deep in the AWS ecosystem. Look at OpenSpec if you want the lightest possible workflow inside an existing repo. The loop (constitution, specify, plan, tasks, implement) is nearly identical across all of them, so switching costs are low.
Does spec-driven development replace vibe coding completely?
No, and treating it as a religion is a mistake. Vibe coding is still the right mode for prototypes, throwaway scripts, and exploration, where the code is disposable and speed of learning is the goal. Spec-driven development earns its overhead on production features, multi-person work, and anything with real edge cases. Strong teams in 2026 use both and switch deliberately.
How does spec-driven development relate to agentic engineering?
Agentic engineering is Karpathy's term for the new default workflow where developers orchestrate AI agents instead of typing most of the code. Spec-driven development is the most concrete methodology for doing that well: the spec is the artifact agents are orchestrated against, and the constitution encodes the oversight rules. If agentic engineering is the job description, SDD is the operating manual.
How long should a spec be?
Long enough that a wrong implementation would visibly violate it. For most features that is one to three pages: a why section, testable acceptance criteria, edge cases, and explicit out-of-scope items. If your spec fits in one paragraph, it is a prompt with better formatting, and the agent is still guessing. *We publish deep dives like this on the Levelop blog every week. If you are preparing for system design interviews or leveling up your engineering career, that is where to find us, or start at levelop.dev.*